


1. 前言
在上一篇的文章中,我们通过qt中的测试成功制作出了小猫的雏形,并且测试了在qt中播放音乐和歌词的功能。接下来的工作就是下载歌曲和歌词了。
对于歌曲和歌词需要从其他的网页上下载,这里主要用到的是hifini和网易云,先从hifini上面下载无损的音乐,但是这个音乐是没有歌词的,因此还需要从网易云上下载歌词,所以这里主要用到的是python的爬虫进行数据的获取。
2. 歌曲下载
因为歌词主要是用的是网易云的歌词,所以从网易云下载歌曲也算是很好的选择,但是网易云的要下载无损的歌曲需要vip才行。因此找了很多的网站才找到一个比较适合的网站能够下载无损的歌曲。
找到合适的下载网站,接下来就可以用爬虫获取数据了
2.1 实现网页搜索歌曲
-
首先就是找到网页搜索的网址和api网址
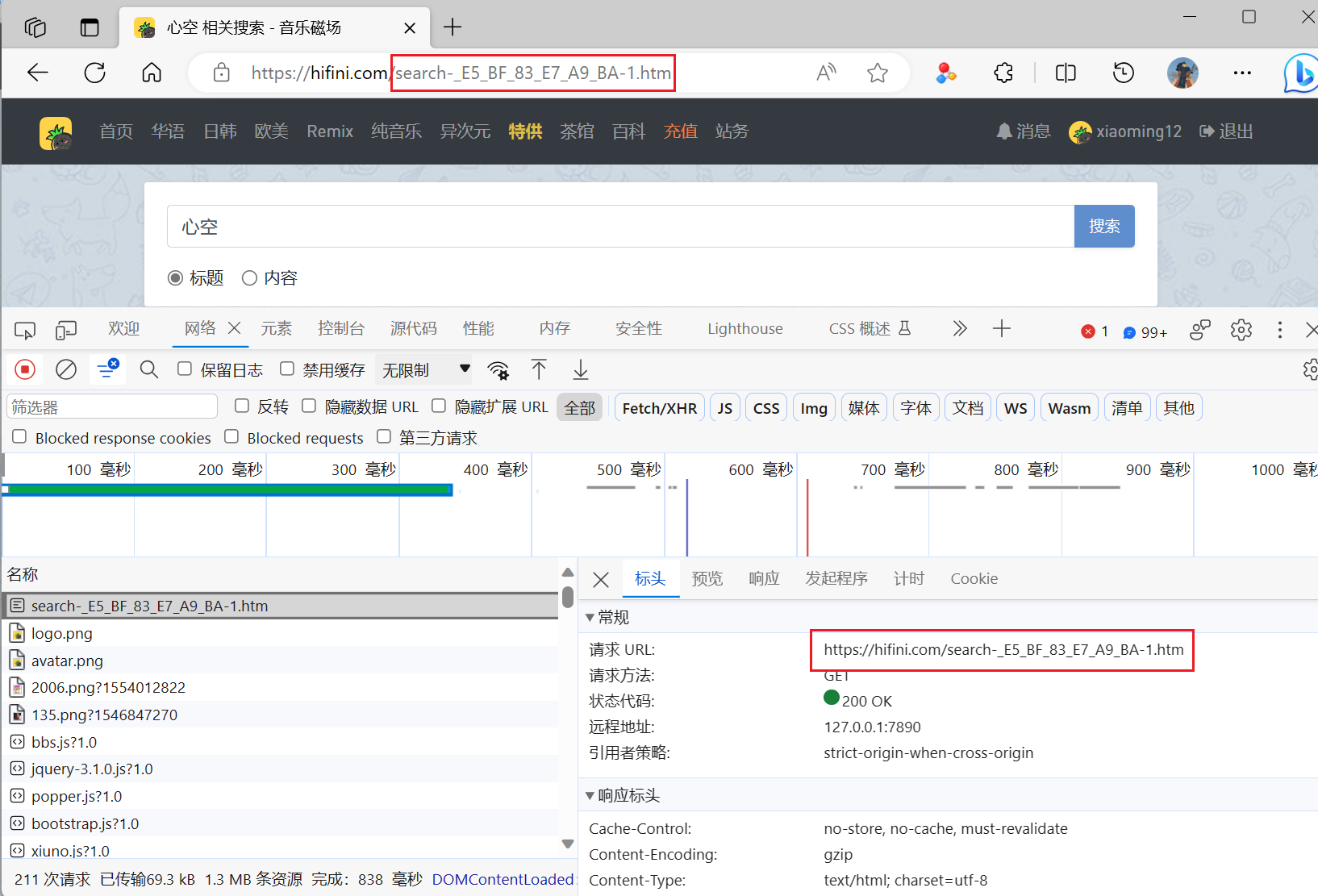
-
但是可以从上图中看到歌曲的名字是乱码的,所以第一步就要找到这个加密逻辑
-
其实这并不是什么加密逻辑,就是把歌曲的名字经过URL编码并且替换了将%替换为_而已
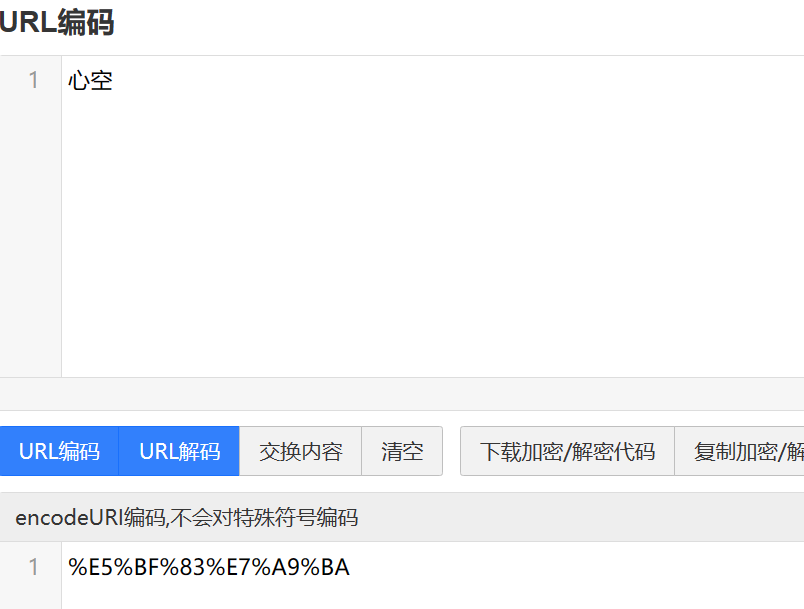
-
接下来就是使用python的requests库调用上面的接口就可以获取到搜索的结果了
2.2 解析搜索结果
-
在获取到搜索结果之后就可以使用python的xpath解析html文件了
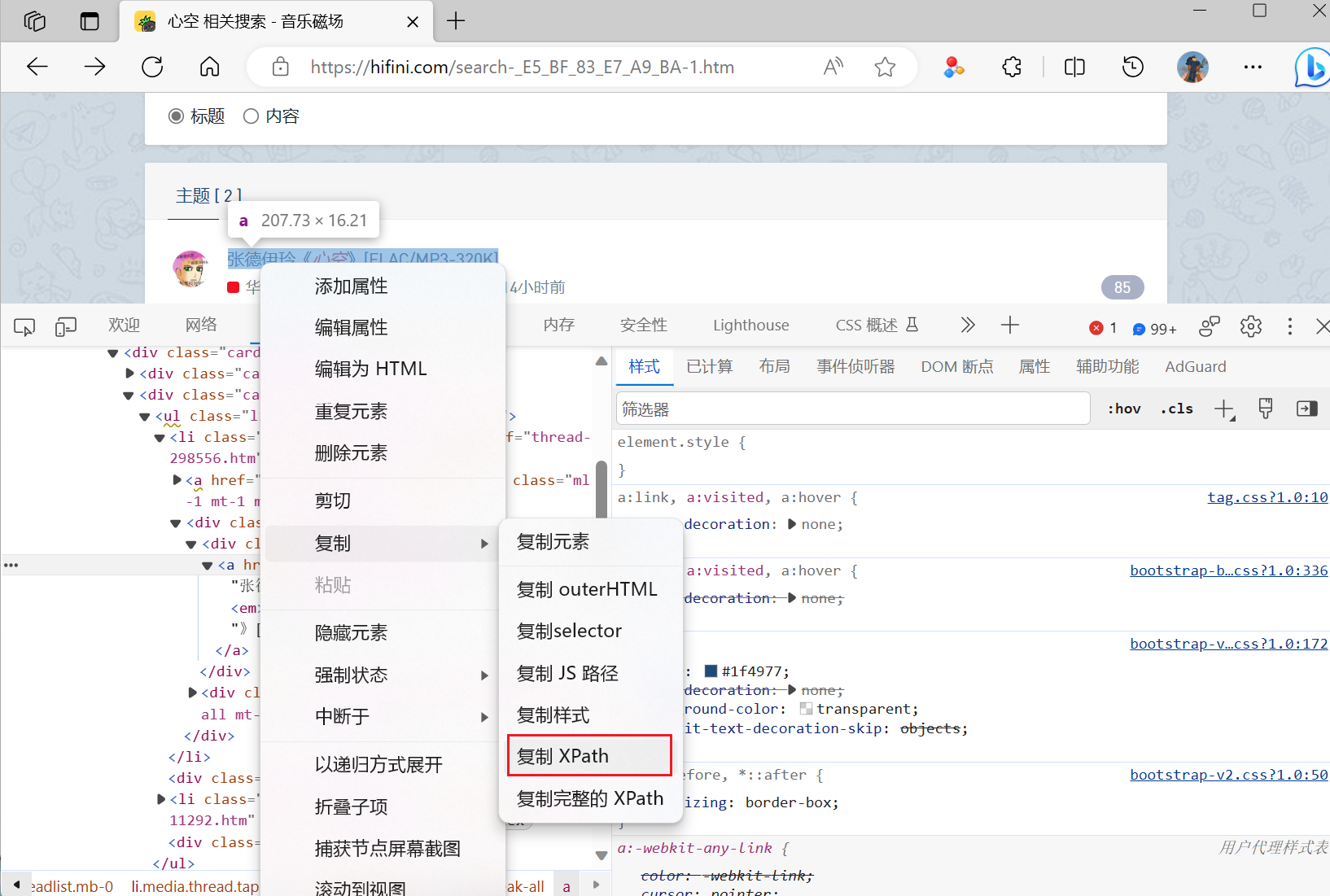
-
这里主要是获取搜索结果的歌曲和作者以及详情页的跳转链接
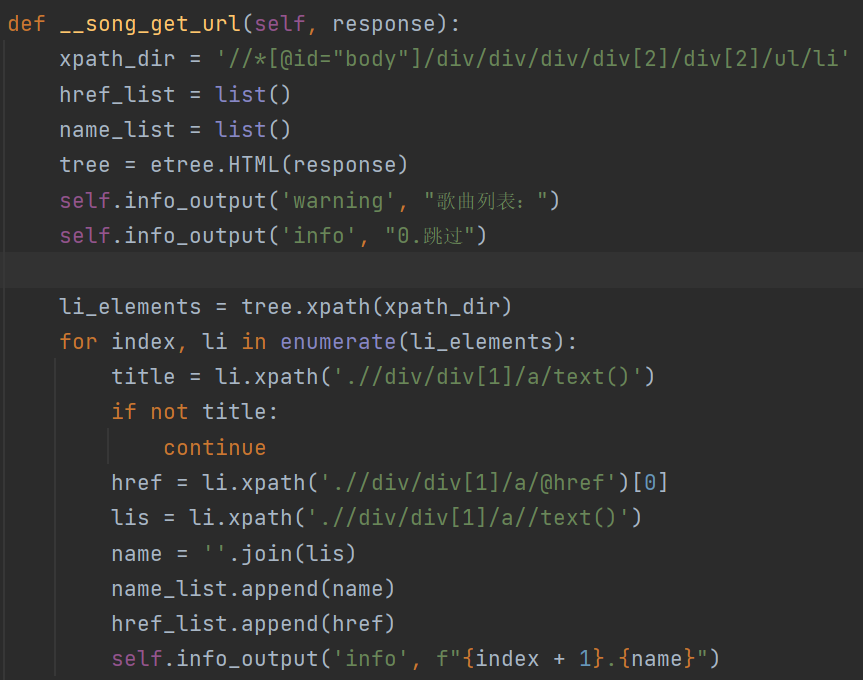
-
因为搜索结果可能不止一个,为了避免下载错歌曲,所以这里还需要我们手动确认一下需要下载的歌曲

2.3 破解跳转加密
-
在上面选择好需要下载的歌曲之后,接下来就是获取选择的歌曲的详情页网页,但是使用python的requests获取网页之后实际显示是这个跳转的页面

-
很明显这是一个重定向的页面,在跳转完成之后网址后面加上了一个验证,这个验证是一个动态的验证,每次进入都是不一样的

-
之前抓取浏览器的网路连接记录都是在浏览器里进行的,但是现在这一个跳转链接,浏览器默认会直接的跳转所以很难看到跳转的时候发生了什么,所以就需要用到专业的抓包工具——[fiddler](Download Fiddler Web Debugging Tool for Free by Telerik)。通过fiddler的抓包可以看到在我们的发送网页的请求之后,返回的内容就是跳转中的字样,并且设置了新的跳转网站
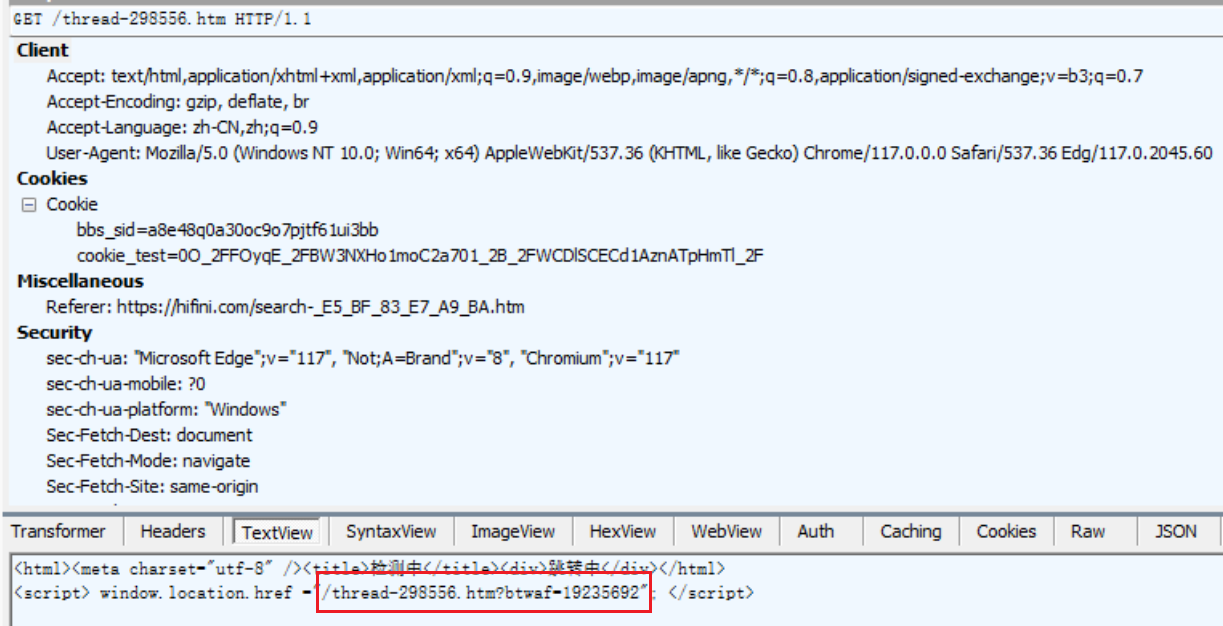
-
如果直接用新的网址去访问网站发现也是不行的,一样会被拦截,通过查看网站的请求参数发现,网页在返回新网址的同时还返回了一个新的Cookie
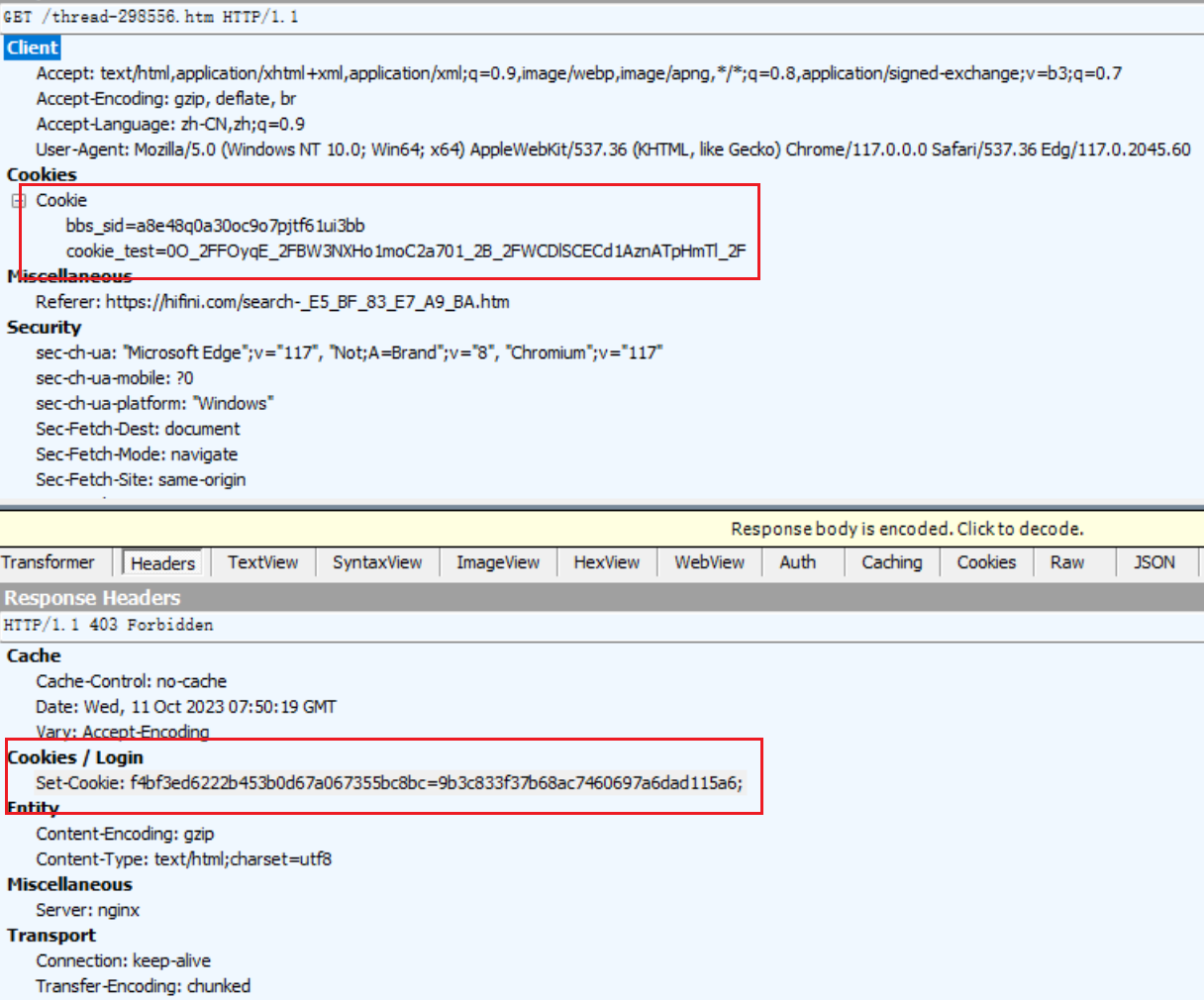
-
查看用新网站请求的参数发现在新的请求中加上了上面返回的Cookie
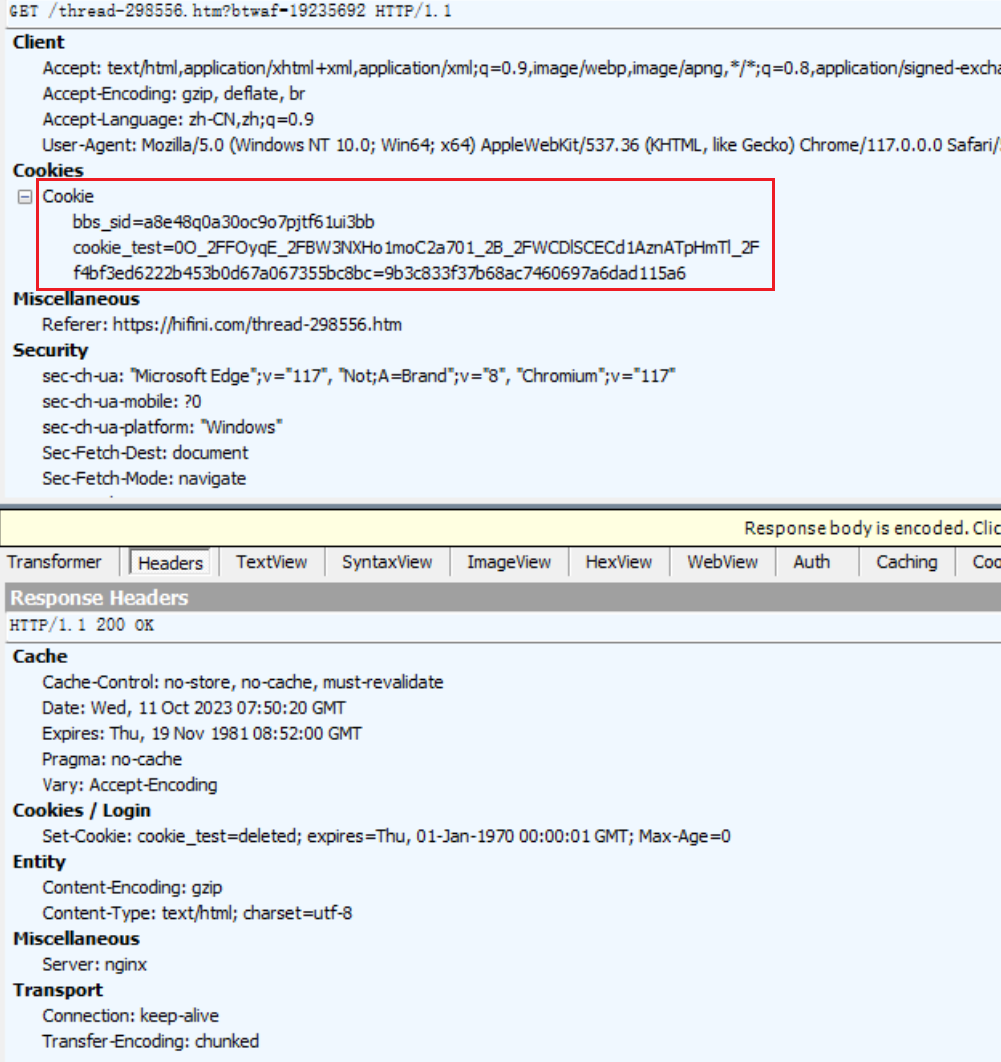
-
尝试在python中获取新的网站地址和新的Cookie去重新请求歌曲的详情页,这样就可以跳过跳转页面直接获取到歌曲的详情页了
url = f"https://hifini.com/{song_url}" response = requests.get(url, headers=self.__header, allow_redirects=False) url_str = response.text.split('window.location.href ="')[1] url_str = url_str.split('";')[0] redirect_url = response.headers redirect_url = redirect_url['Set-Cookie'].split(";")[0] self.__header["Cookie"] = self.__header["Cookie"] + "; " + redirect_url url = f"https://hifini.com{url_str}" response = requests.get(url, headers=self.__header, allow_redirects=False)
2.4 解析歌曲详情页
-
本来解析歌曲的详情页和上面解析歌曲的搜索结果是一样的操作,但是在获取歌曲的下载链接时出现了一些问题。在之前的操作中只需要获取xpath链接就好了,但是在这里的网页源代码里面发现网页上显示的提取码和网页源代码中的提取码是不一样的,源代码中的提取码多了很多的其他的字符
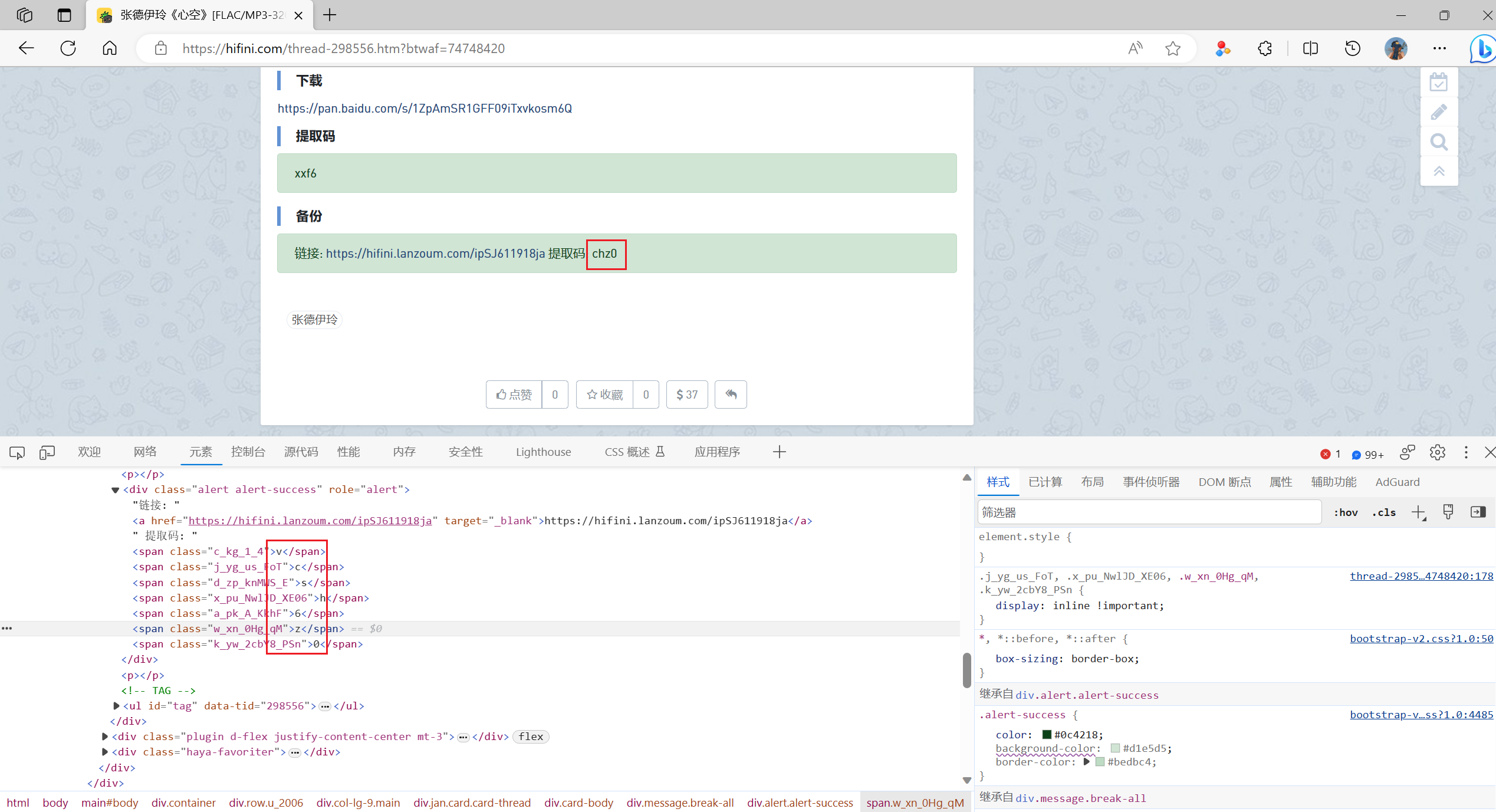
-
将源代码直接保存到本地,然后直接运行。因为缺少了很多的js和css文件所以在本地运行的不会向服务器请求这些文件,所以就变成了没有排版的这个样子。在这里面发现提取码还是成功显示了出来,所以说明这个提取码的显示其实就是这个网页的某些代码处理的
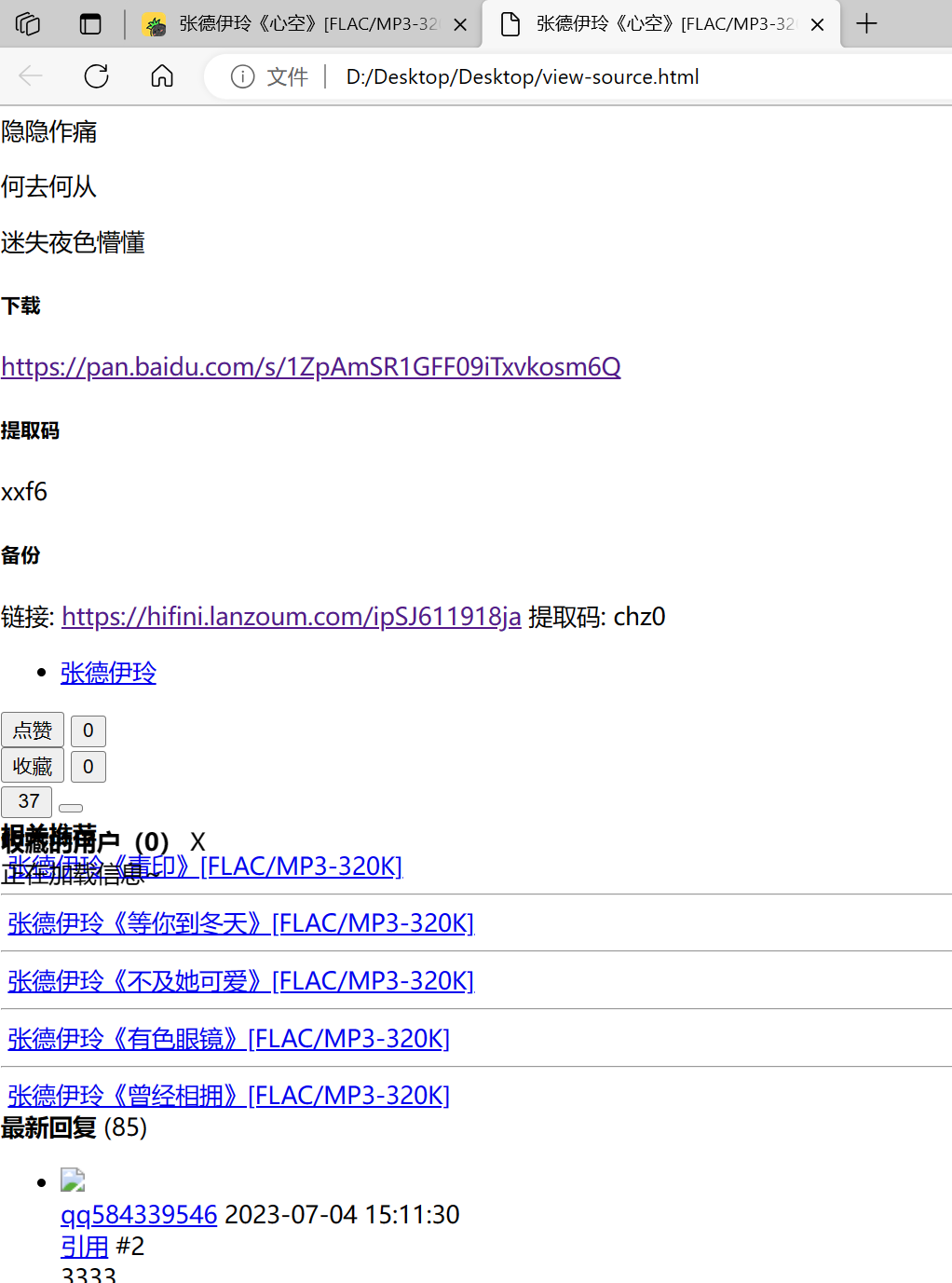
-
经过一顿寻找,在源代码中找到这样一段style的代码。代码中的
display: inline其实就是显示在网页上的提取码,display: none中的内容就是在源代码中显示的提取码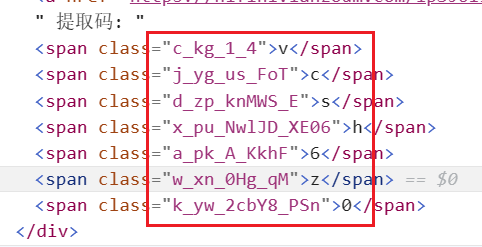
<style> .x_nr_S_PI, .u_ap_acY4_qXr4S, .f_cm_reuDf_U6SNi, .r_yx_iOF_J { display: inline !important; } .d_ro_JS2qO_2t, .g_ov_ukm_O, .p_fv_C4_Sb5T, .t_en_yWu2u_tM, .q_ga_fdVw_Ov, .g_wg_B2_twCR, .v_ti_Hnv_x { display: none !important; } </style> <style> .l_ki_kQszx_ng1tQ, .c_pq_4_7xO9L, .z_dc_M6xC_vg, .i_wk_PIJ_w { display: inline !important; } .k_wp_lxT_Eh4Uf, .c_jx_VTwV2_j, .g_bm_4jh_Ouvaw, .w_kh_I_cD, .s_bh_HAT_Ar { display: none !important; } </style>尝试使用python实现上述的操作。这样就可以成功获取到下载的网址和提取码了
url = f"https://hifini.com{url_str}" response = requests.get(url, headers=self.__header, allow_redirects=False) tree = etree.HTML(response.text) link = tree.xpath(f'{path}//text()')[1] password_list = tree.xpath(f'{path}/span') password_dict = dict() for li in password_list: text_pass = li.xpath('.//@class') text = li.xpath('.//text()') if not text_pass: break password_dict[text_pass[0]] = text[0] passw = tree.xpath('//*[@id="body"]/div/style[2]//text()')[0] str_list = passw.split("{display:inline !important;}")[0].split(",") password = "" for li in str_list: match = li.split(".")[1] password = password + password_dict[match]
2.5 下载歌曲
-
点击上面获取到的下载链接之后就可以跳转过去了
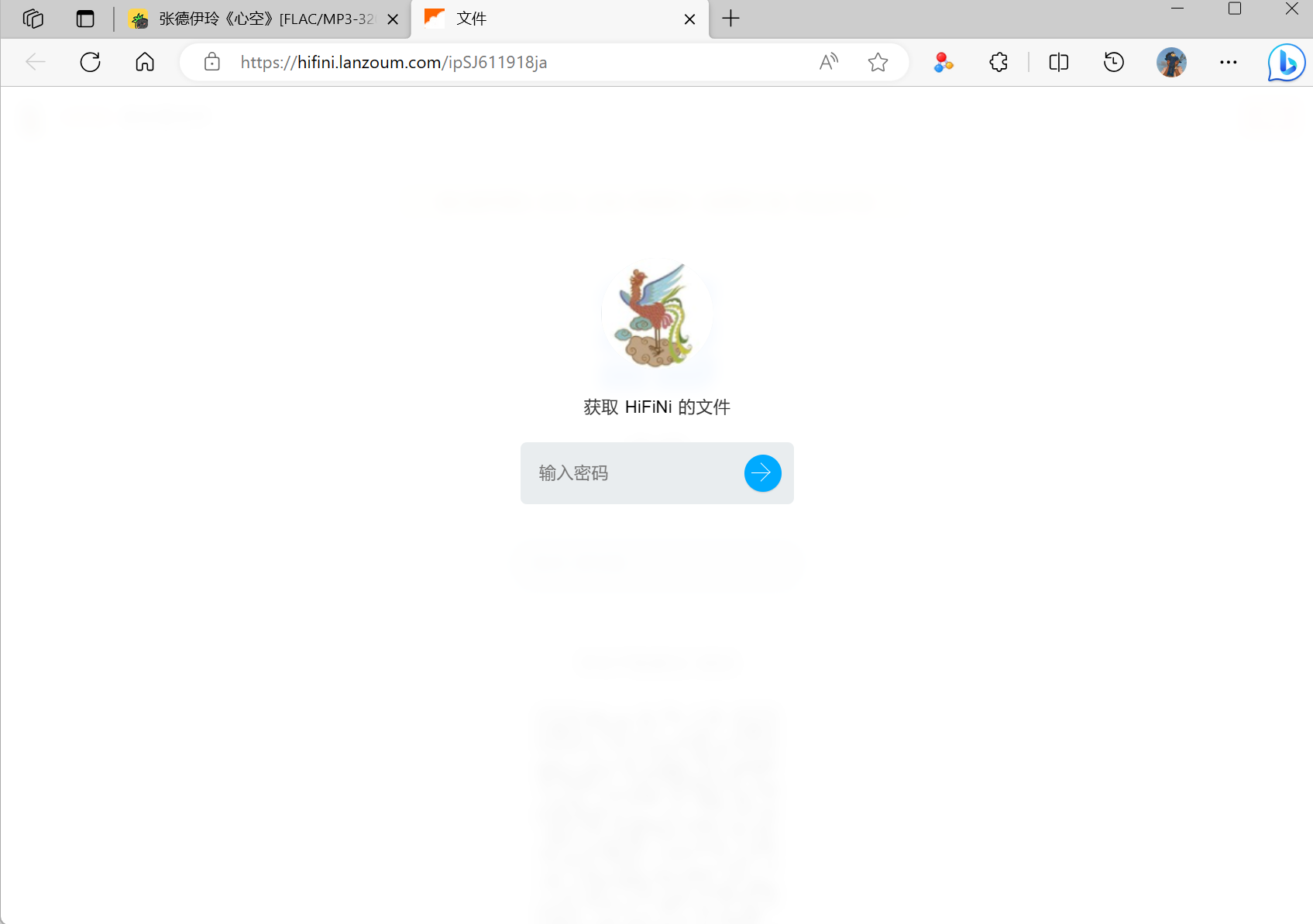
-
输入之前获取到的提取码理论上来说就可以获取到向服务器发送提取码验证的网址,然后服务器会返回歌曲的下载链接。但是在向服务器提交的表单中出现了一串字符,因为这个字符串每次提交都是不同的,因此就需要知道这个字符串的怎么来的
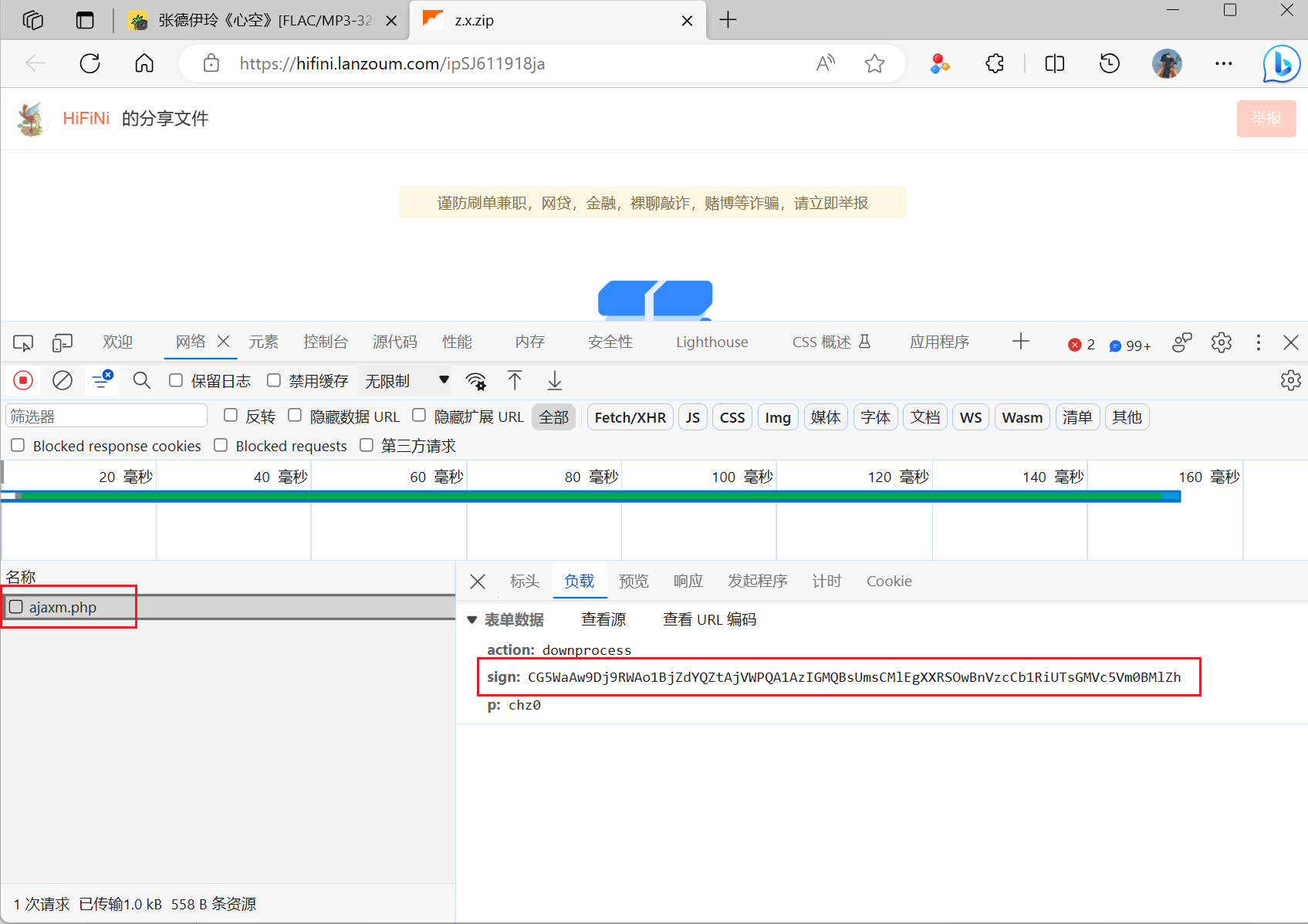
-
这个参数在输入提取码的页面的源代码中是可以找到的,在获得所有的参数之后就可以直接调用api获取到压缩包的下载链接了
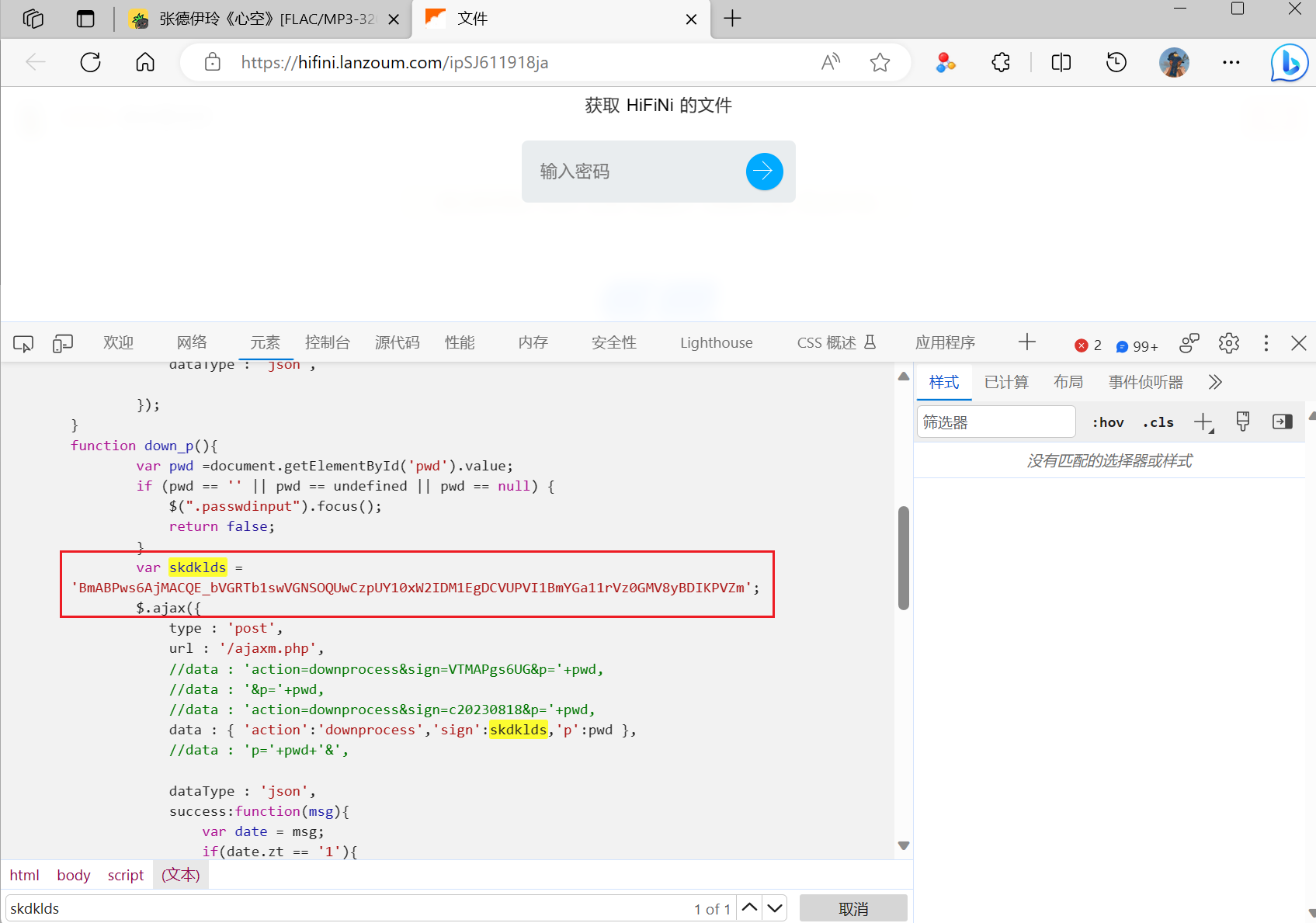
-
在输入提取码之后,从返回的参数中就可以获取到下载的链接了
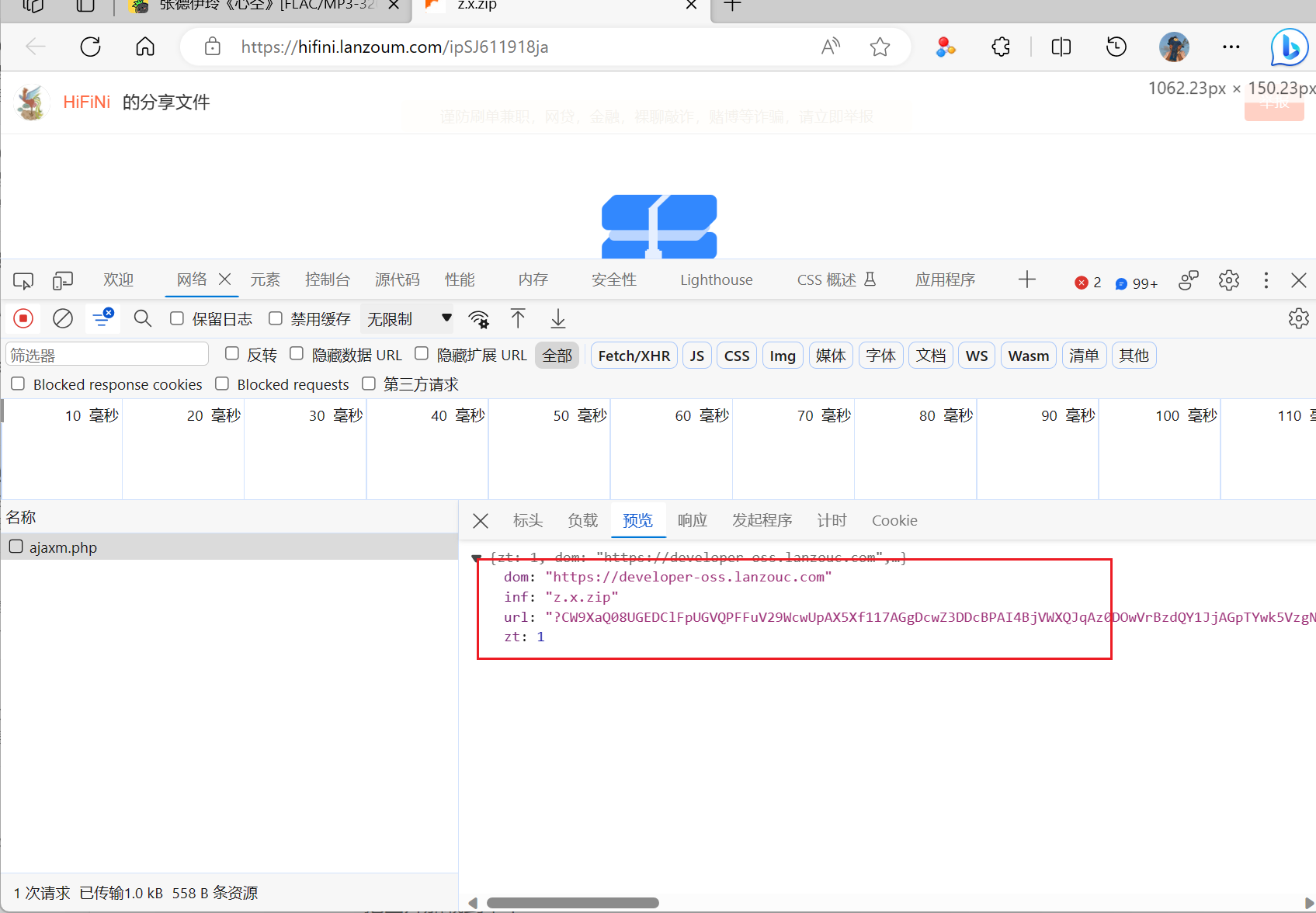
-
其实上面获取到的下载链接还不是真实的下载链接还需要经过一次跳转之后才可以获取到真实的下载链接
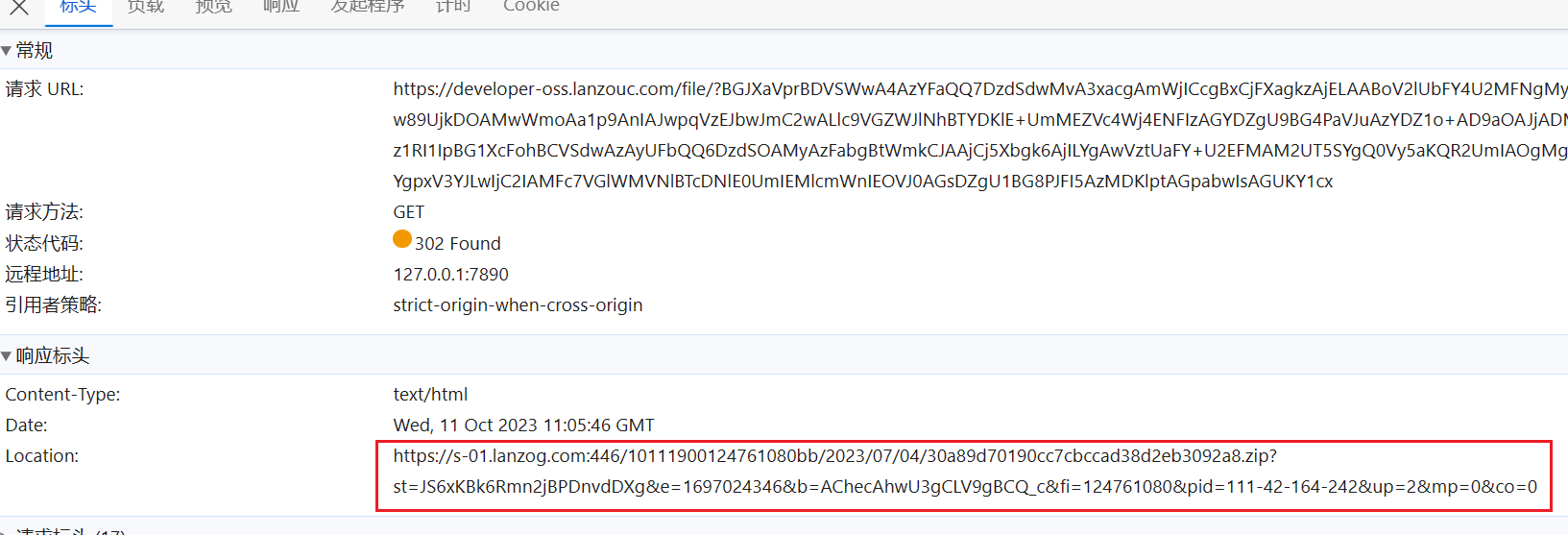
-
使用python实现上述的过程,这样子我们就可以成功的下载到歌曲文件了
url, password = self.__song_link_select(song_url) if url is None: return None response = requests.get(url, headers=self.__header) if response.status_code != 200: self.info_output("error", "song_download:获取网页失败!") return None tree = etree.HTML(response.text) password_primary = tree.xpath('/html/body/script//text()')[0] title = ''.join(password_primary) sign = title.split("skdklds = '")[1].split("';")[0] zip_url = "https://hifini.lanzoum.com/ajaxm.php" data = f"action=downprocess&sign={sign}&p={password}" res = requests.post(zip_url, headers=self.__header, data=data) json_data = json.loads(res.text) file_url = f"https://developer-oss.lanzouc.com/file/{json_data['url']}" header1 = { "Cookie": "down_ip=1", "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.47" } file_data = requests.get(file_url, headers=header1, allow_redirects=False) file_redirects = file_data.headers["Location"] song_name = song_name.split("[")[0] self.info_output('info', f"正在下载 {song_name} ...") folder = os.path.exists(f"{self.__souce_path}music_zip") if not folder: # 判断是否存在文件夹如果不存在则创建为文件夹 os.makedirs(f"{self.__souce_path}music_zip") # makedirs 创建文件时如果路径不存在会创建这个路径 file = requests.get(file_redirects) with open(f'{self.__souce_path}music_zip/{song_name}.zip', 'wb') as f: f.write(file.content) self.info_output('info', f"{song_name} 下载完成!")
3. 歌词下载
这里使用的是从网易云下载歌词,但是因为网易云的歌词是加密过的,所以还需要对网易云进行js逆向,破解出来网易云的加密过程这样才能成功获取到歌词
-
通过对网易云页面的所有请求链接的查找,终于到找了可以返回歌曲歌词的链接,理论上通过这个链接就可以获取任何歌曲的歌词了
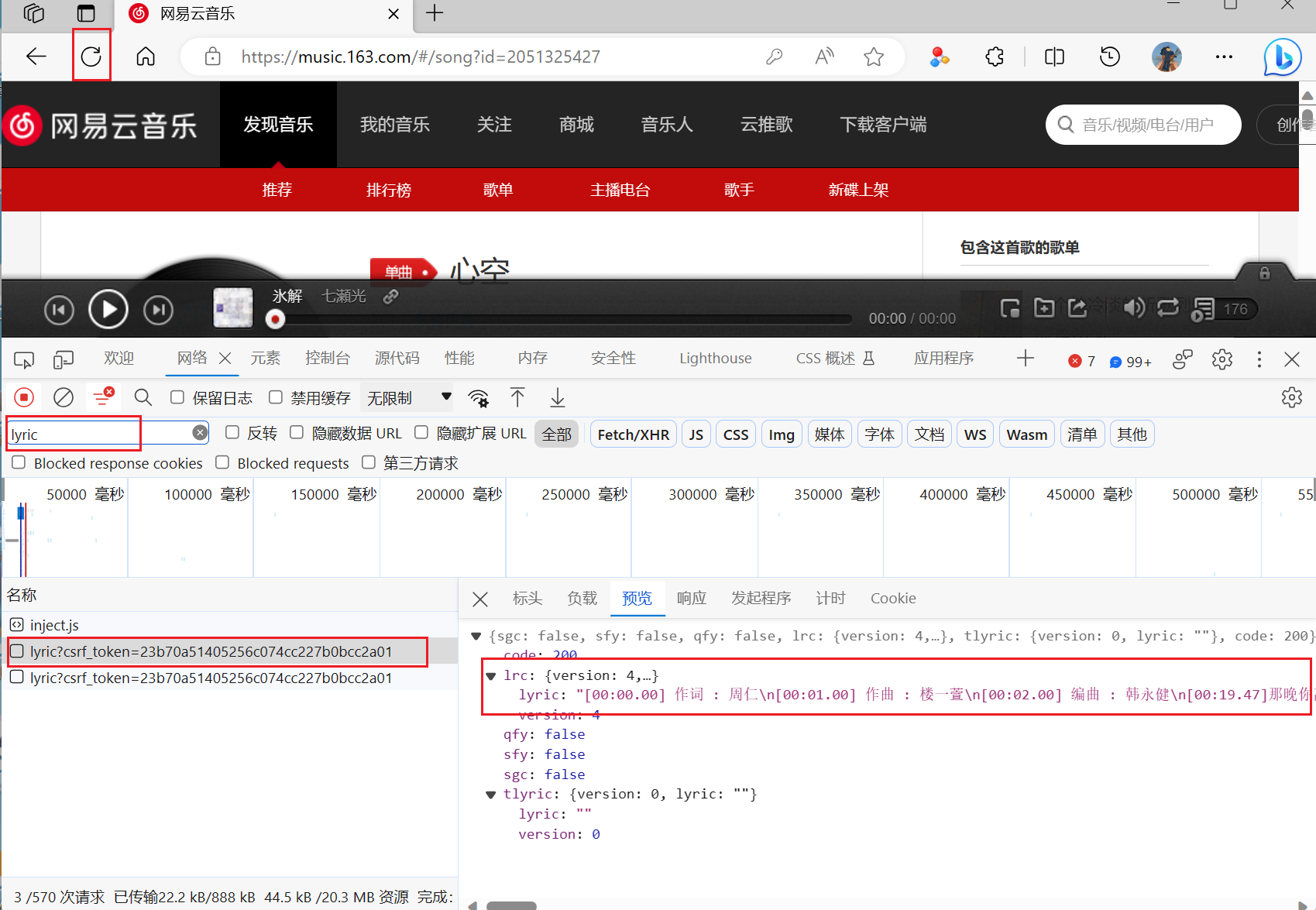
-
通过多次实验,发现在请求的参数中一直都需要两个参数params和encSecKey,这两个参数的数据都是经过加密的,因此下面的工作就是要解密这两个参数

-
点击发起程序中的第一个请求调用堆栈
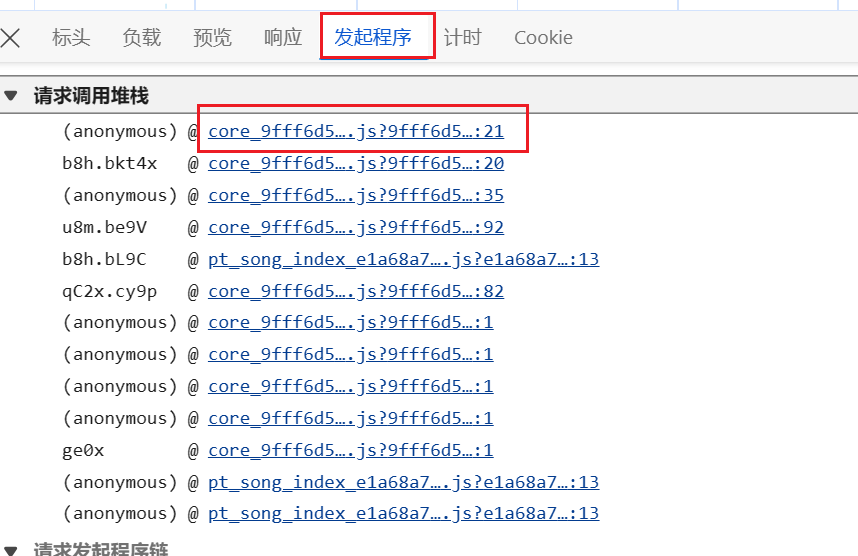
-
这一个就是发送请求获取的歌词的js代码,在这个地方打一个断点
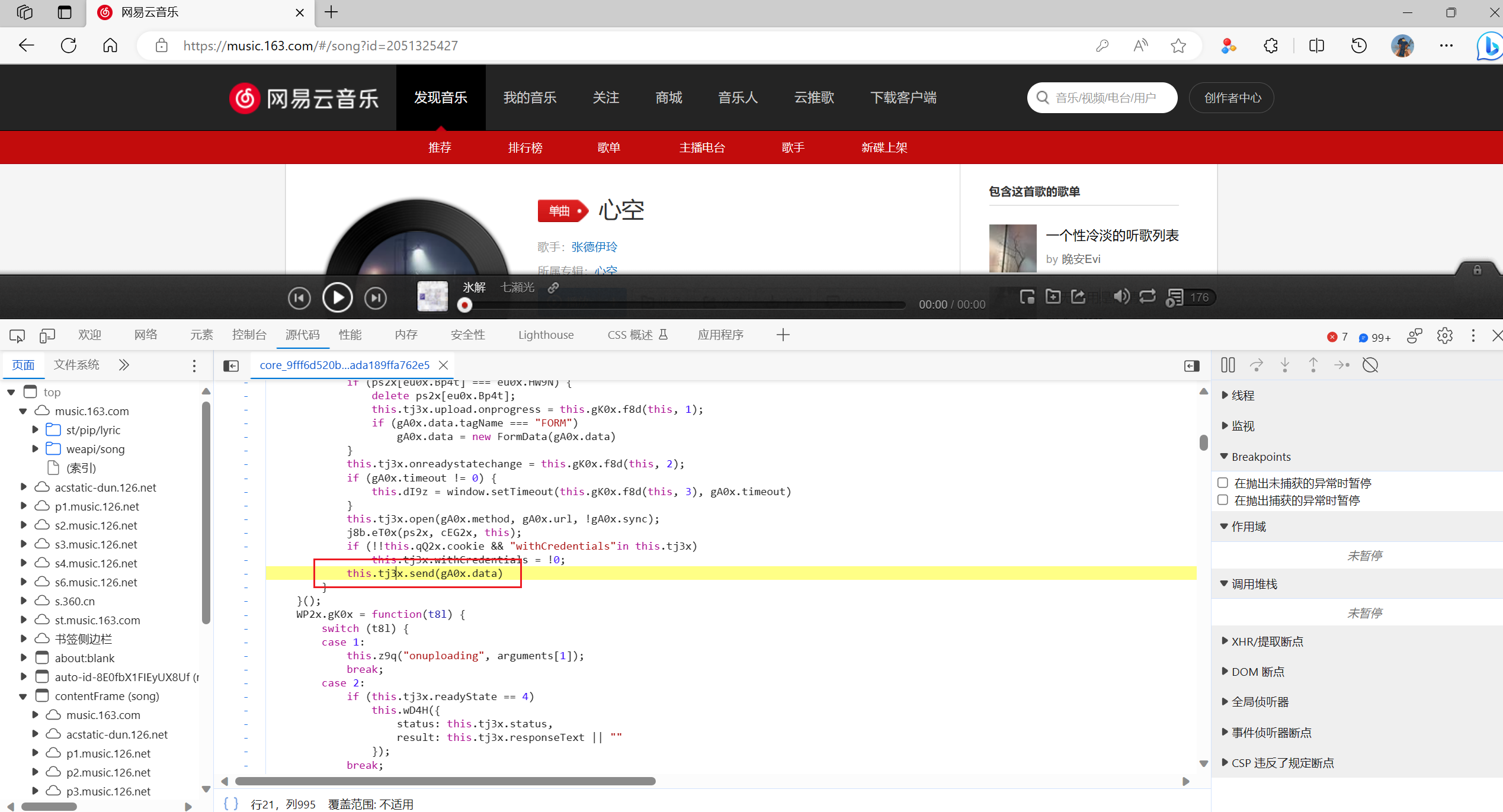
-
刷新页面,不断的点击右侧蓝色按钮并观察是否有lyric开头的链接发出,这个就是要找的链接
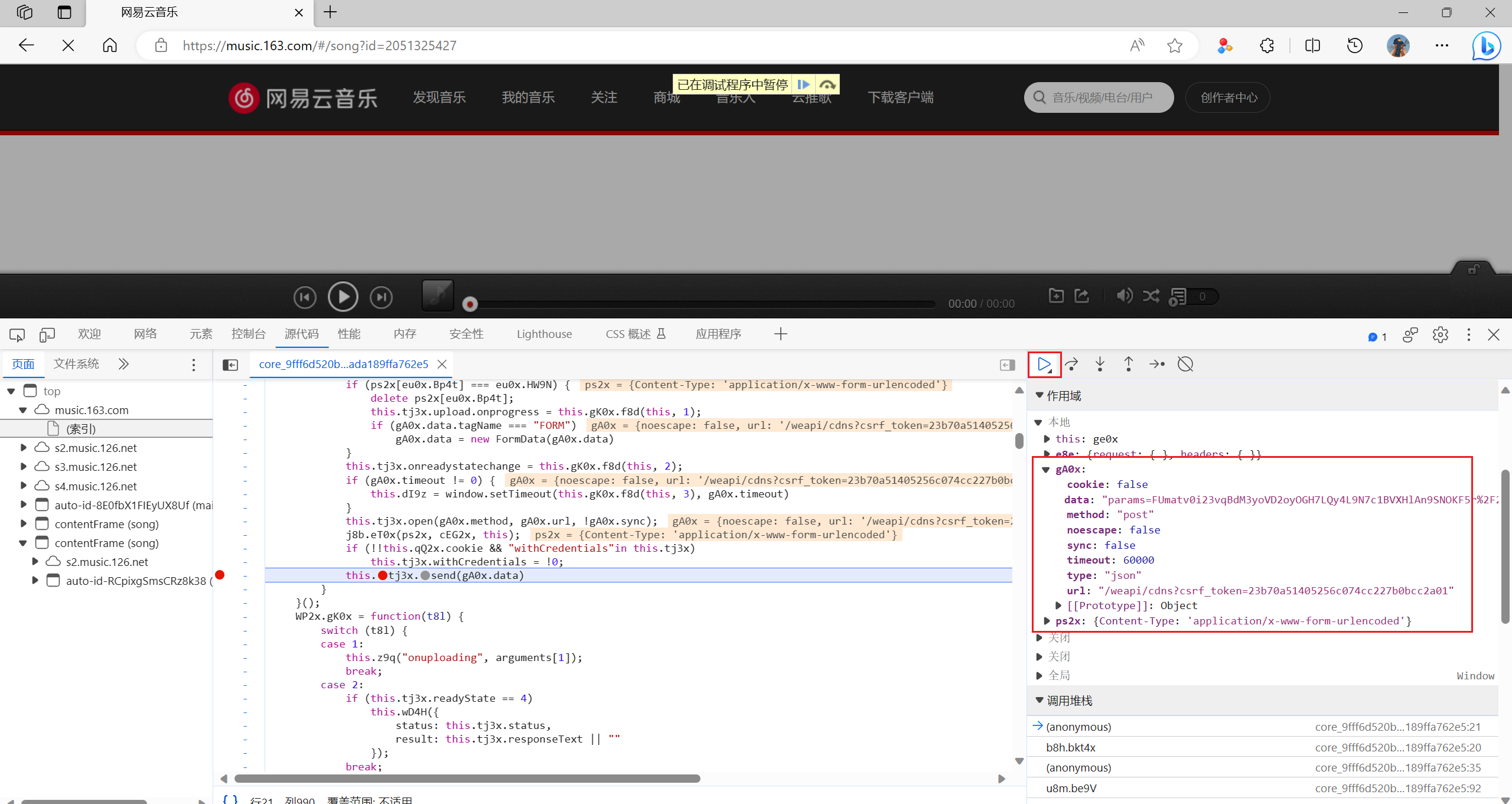
-
找到之后一次点击下面的调用堆栈,直到上面的加密的数据不在出现
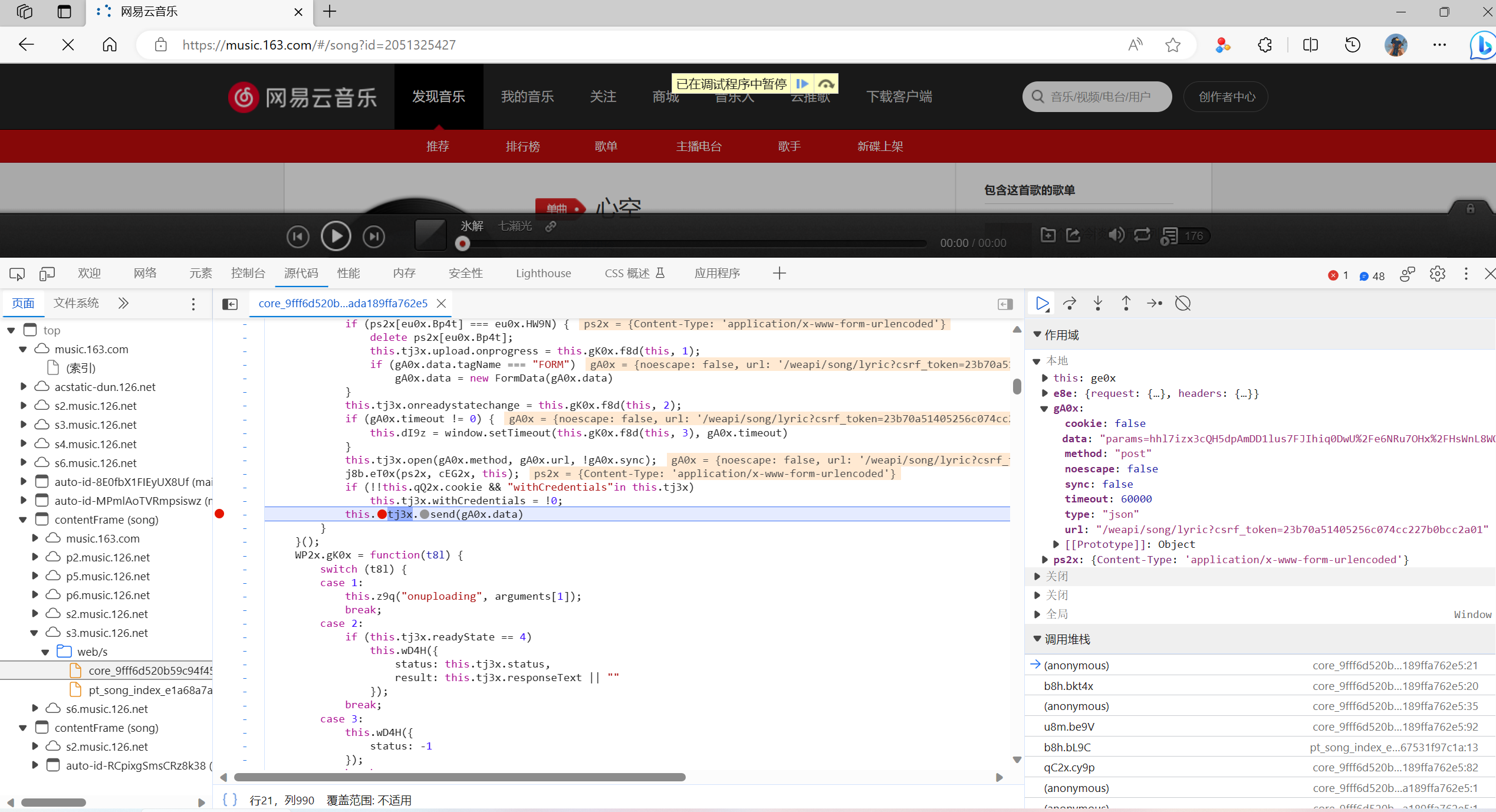
-
这样子就成功找到了加密参数的代码位置了
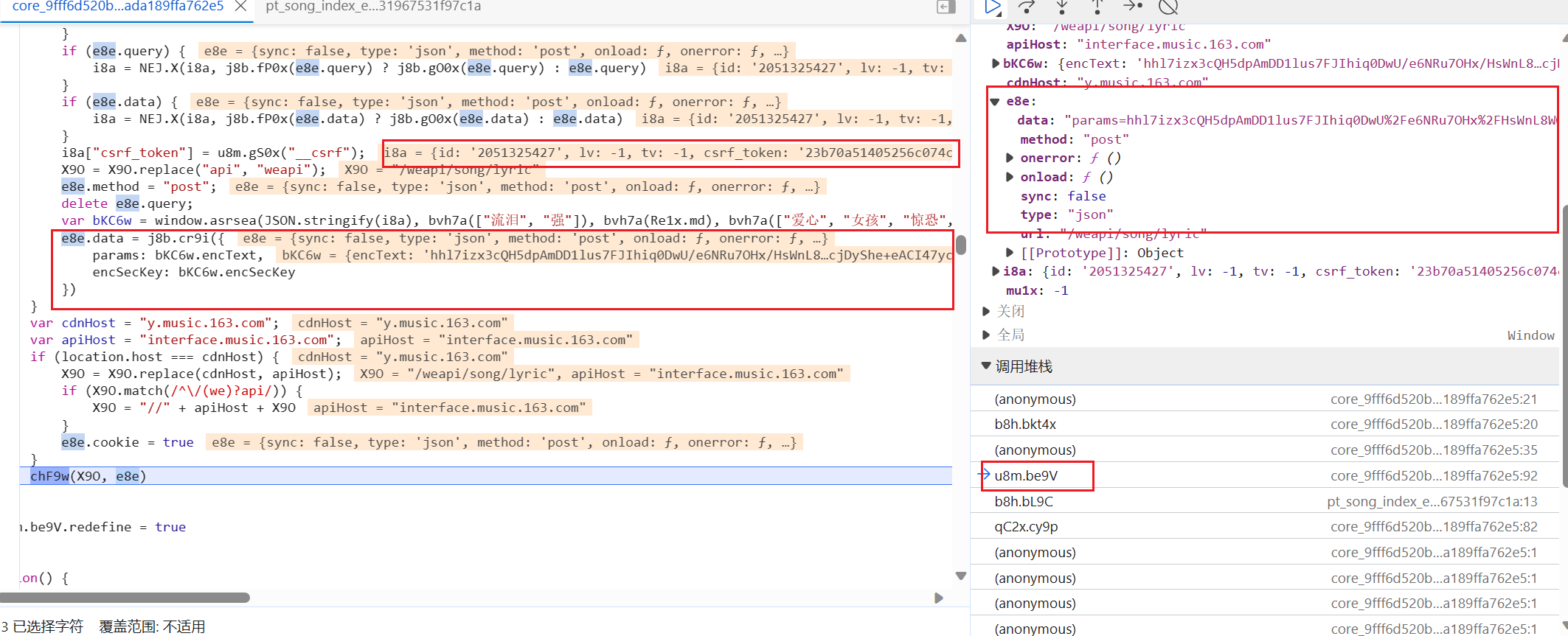
通过上面的查找发现,它们俩的值分别为
bWv0x.encText,bWv0x.encSecKey正好对应上请求中的两个参数,现在就需要对这两个参数做分析,看他们是怎么一步步被计算出来的 -
bKC6w其实就是由
window.asrsea(JSON.stringify(i8a), bvh7a(["流泪", "强"]), bvh7a(Re1x.md), bvh7a(["爱心", "女孩", "惊恐", "大笑"]));这个函数经过里面的几个参数计算出来的。bvh7a()也是一个函数,但是里面的参数都是固定的。而i8a["csrf_token"]里面的数据是window.asrsea()函数的第一个参数,这一串应该就是要获取的歌曲的歌词id(我猜的~)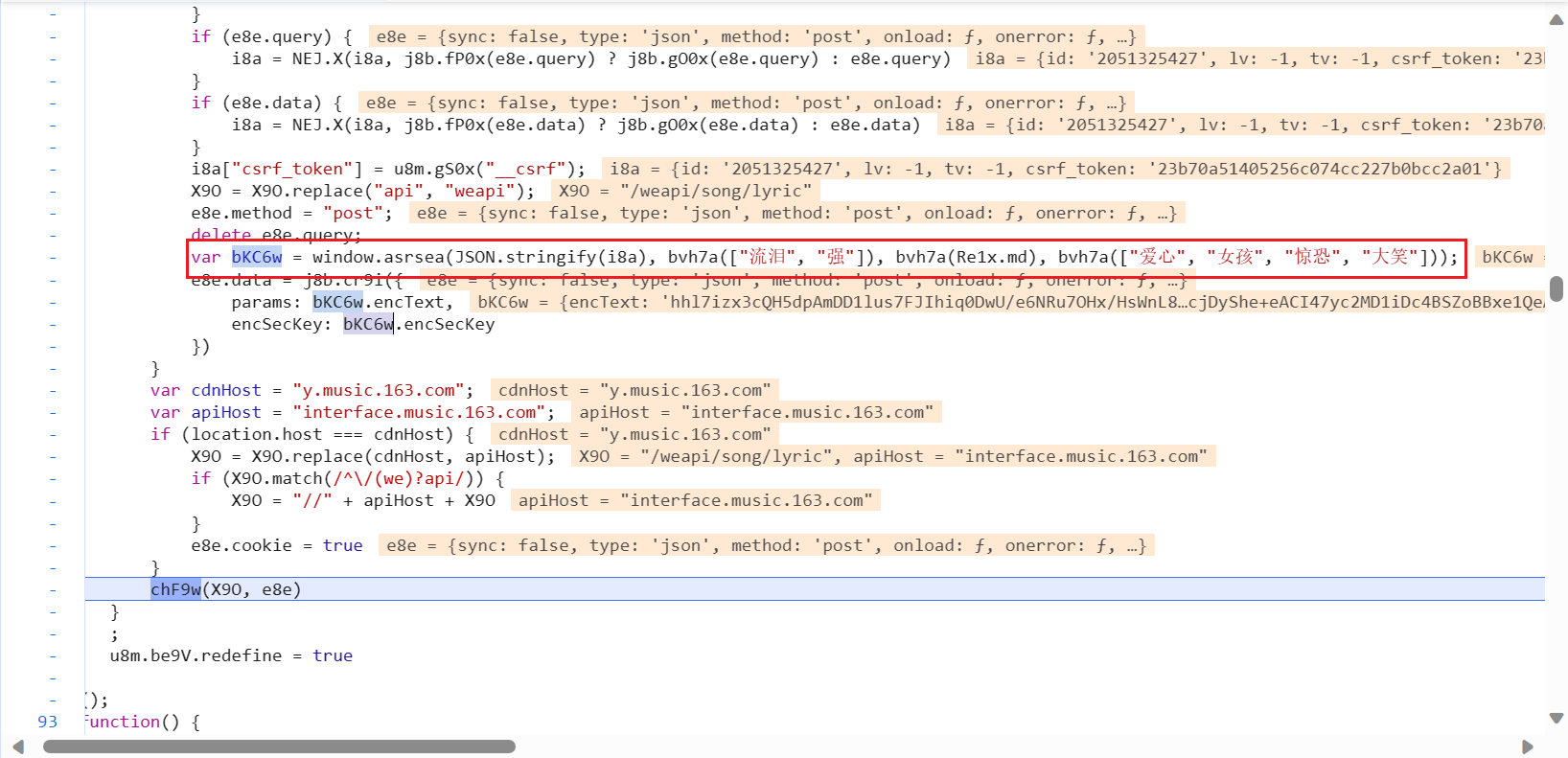

-
全局搜索一下这个函数。找到这个函数之后打上断点然后重新运行,观察各个参数的值和传递情况
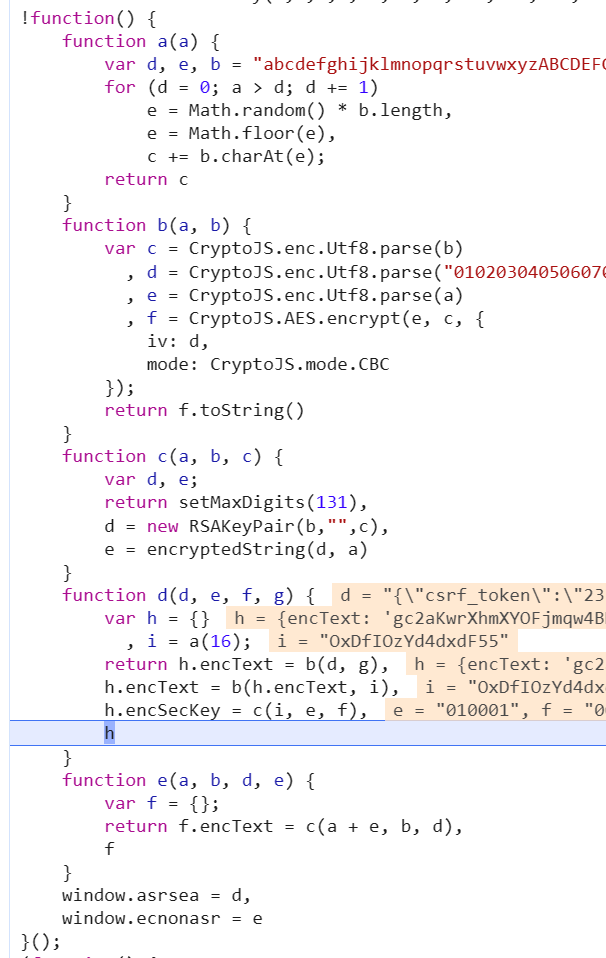
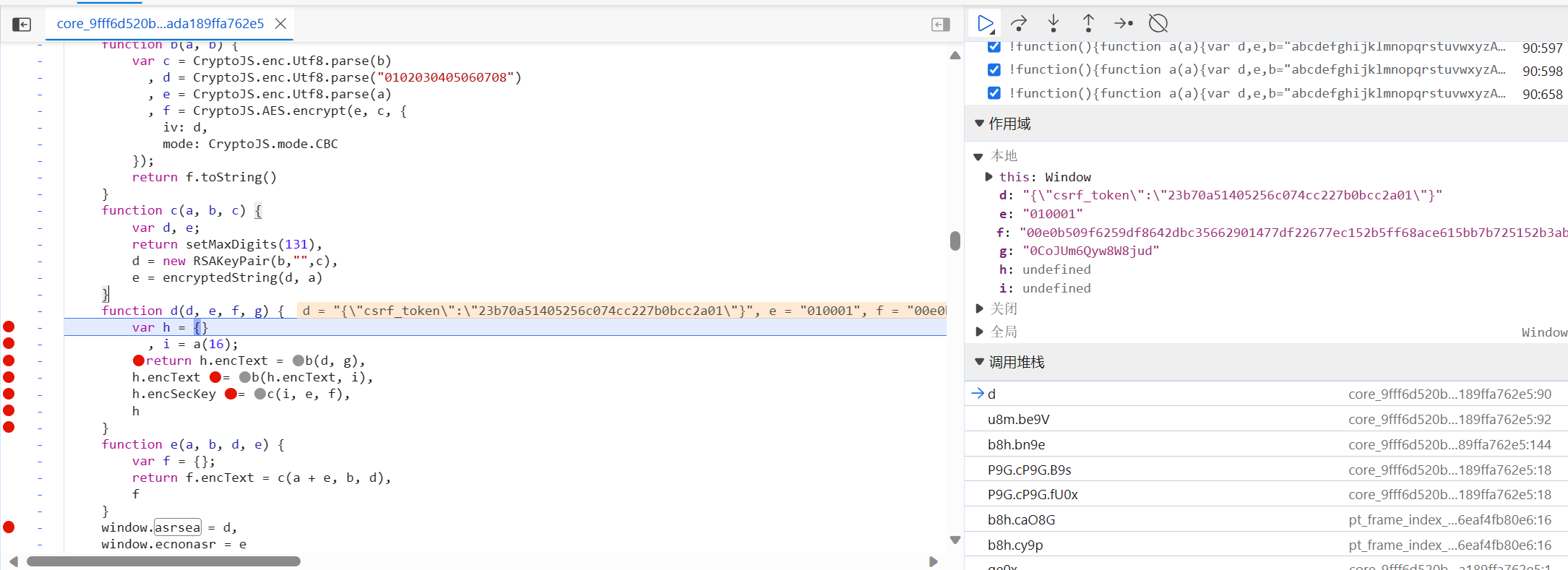
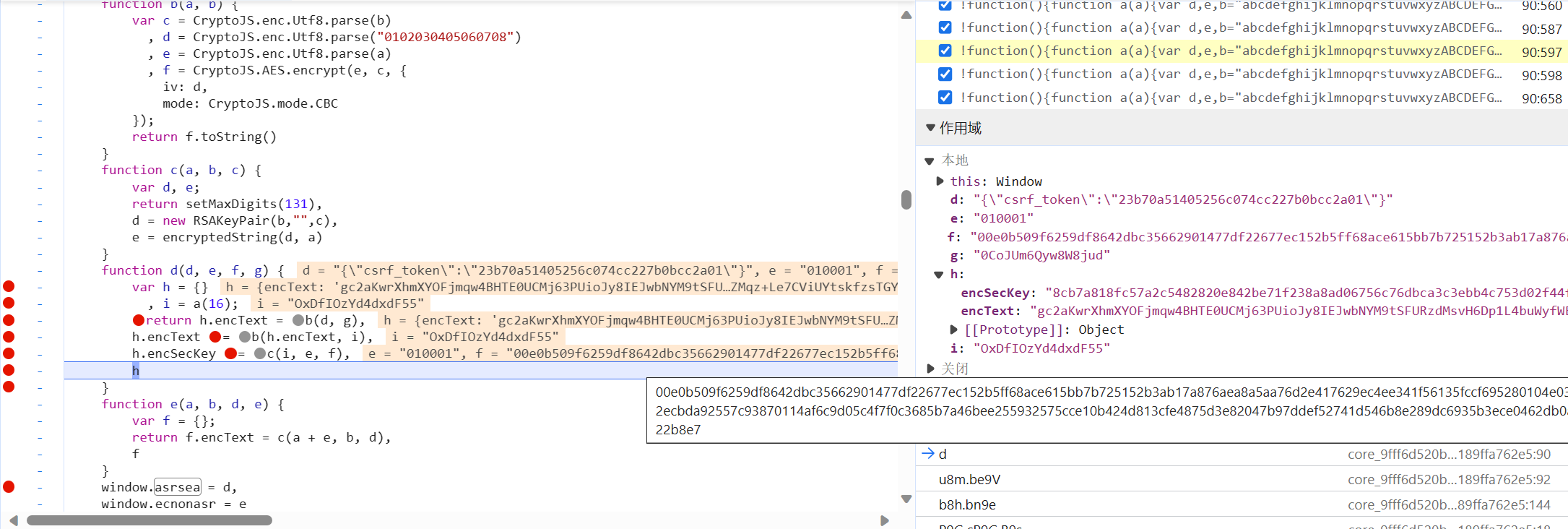
通过分析上面的a、b、c、d函数,可以发现a函数是取随机长度的字符串,b函数是AES的加密,c函数有点看不懂是什么操作,但是既然传进去的三个参数多次实验都是固定的,那么它的返回值应该也是固定的,而encSecKey的值等于它的返回值,也就是说encSecKey可以是固定的。而i值是由a函数随机生成的,那么取它的一个返回值即可。
-
使用python实现一下上面的代码,这样就可以愉快的下载网易云的歌词了
def __to_16(self, data): len1 = 16 - len(data) % 16 data += chr(len1) * len1 return data def __encryption(self, data, key): iv = '0102030405060708' aes = AES.new(key=key.encode('utf-8'), IV=iv.encode('utf-8'), mode=AES.MODE_CBC) data1 = self.__to_16(data) bs = aes.encrypt(data1.encode('utf-8')) return str(b64encode(bs), 'utf-8') def __get_enc(self, data): param4 = '0CoJUm6Qyw8W8jud' enc = 'g4PXsCuqYE6icH3R' first = self.__encryption(data, param4) return self.__encryption(first, enc) def __write_file(self, path, lis): with open(path, 'ab') as f: f.write('\n'.encode()) f.write(lis.encode()) def __get_encryption_arg(self, song_id): param1 = {"csrf_token": "23b70a51405256c074cc227b0bcc2a01", "id": f"{song_id}", "lv": -1, "tv": -1} data = json.dumps(param1) # 对请求参数的加密 params = self.__get_enc(data) data = { 'params': params, 'encSecKey': 'bb20ee9409e57057e4d1b55e4d77c94bff4d8cbf181c467bbd3fa156e3419665c6c1e643621d5d82c128251fb85f0cb34d4f08c88407b4148924ffa818f59a64b3814784e7e3837bad4f6f9690cb2cf721d9ea1af12c16a32a9df00be710b70ee8ed32036cc6a465b28ef43f4382cbcb4595b3121be75ecba9171876b611b8fc' } headers = { 'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.47" } return data, headers def get_lyric(self, song_name, song_id, song_path): path = f"{song_path}music/{song_name}" name = self.__direct_search(path) path_dir = path + f"/{name}.lrc" url = 'https://music.163.com/weapi/song/lyric?csrf_token=23b70a51405256c074cc227b0bcc2a01' data, headers = self.__get_encryption_arg(song_id) response = requests.post(url=url, data=data, headers=headers) dict1 = json.loads(response.text)
4. 单歌曲搜索下载
单歌曲的搜索
- 歌曲的搜索首先就要先从网易云里面搜索,因为还需要从网易云下载歌词,所以必须要在网易云中搜索到歌曲才是可以下载的
- 如果在网易云中搜索到歌曲,在hifini网站中没有搜索到,则可以选择是否从网易云中下载歌曲
- 如果在网易云中没有搜索到,在hifini网站中搜索到,则不能下载
单歌曲的下载
- 一种是在通过网易云下载,这种方式下载方式方便快捷,但是下载的歌曲是经过压缩的音质不太好
- 另一种是通过hifini网站下载,这种方式下载方式复杂一些而且不稳定,但是下载的歌曲是没有经过压缩的音质非常的好
5. 批量歌曲搜索下载
批量歌曲的匹配
- 这里批量歌曲的使用是通过获取网易云的歌单,通过获取歌单中歌曲的名字,然后在hifini网站网站中搜索进行匹配
- 通过对网易云和hifini网站中的歌曲的匹配,如果匹配成功则将hifini网站歌曲的网站的网址和网易云歌曲的id插入到数据库中,如果匹配不成功则只会将网易云的id插入到数据库中
- 在匹配成功后不会立刻进行歌曲的下载,而是只是存储歌曲的下载地址或者是下载信息,在匹配成功会进行统一的下载
批量歌曲的下载
- 在所有的歌曲匹配成功之后就可以进行下载了
- 首先就是根据数据库中插入的数据,如果是从hifini网站下载则会根据上面的获取链接的过程进行下载,如果是从网易云下载则会按照上面的破解方式从网易云下载歌曲
- 这里使用的是多线程进行下载可以大大加快下载速度
- 在歌曲下载完成之后会读取数据库中对应的歌曲的网易云id号,然后从网易云下载歌词
- 录制视频,用pr将视频分解成图片
- 用ps将图片中的猫抠出来
- 把图片加载到qt中
- 测试qt中播放歌曲和加载歌词
- 编写python脚本
- 从网易云收藏列表中获取歌曲列表
- 下载歌曲
- 用requests获取搜索网页
- 使用python封装搜索功能
- 获取搜索的结果和链接
- 在结果中获取需要下载的歌曲的链接
- 在网页源码中的提取码是有乱码的
- 找到css中加载的的提取码
- 根据歌曲的链接的提取码跳转到下载页面
- 从下载页面中获取密钥
- 输入邀请码和密钥获取下载链接
- 根据下载链接跳转到真实的下载链接
- 下载文件
- 下载歌词
- 破解网易云加密js加密协议
- 根据歌曲的id获取歌词
上传歌曲
搜索歌曲
下载歌曲
歌曲名
歌曲状态 三个
评论区