


前言
在之前的时候就准备做一个能随时听音乐的功能,最开始想做一个桌面端的宠物小猫咪,在里面加入音乐播放器的功能,当时是打算使用qt制作的,但是无奈使用qt制作之后界面实现是丑到爆表,加装饰之类有需要到处找素材,无奈到现在也没找到合适的素材,于是只能暂时烂尾,但是音乐的功能还是迫切的需要的,在今年暑假的时候打算开一个新坑(bushi)--用微信小程序做一个,正好可以把服务器监控探针(悄悄透漏一下这个时候已经完成并上架了)的功能也加进去,那就开搞吧!!!
每个人的听歌习惯都不一样,对大多数人来说,QQ音乐,网易云音乐等音乐软件,无论pc端还是手机端都能满足听歌需求,这里我分享一下自己的听歌心得体会,和大家交流交流,不喜互喷~
音乐作为精神食粮不可不食。老早以前,网吧里随便就能下音乐,但是随着时代的发展,由于版权问题,越来越觉得在线听音乐和下载音乐让人头疼。音乐作为精神食粮不可不食。老早以前,网吧里随便就能下音乐,但是随着时代的发展,由于版权问题,越来越觉得在线听音乐和下载音乐让人头疼。好在还是有那么一群音乐的爱好者愿意整理琳琅满目的歌曲并且免费提供下载,于是开始混迹网络收集歌曲,但是随着收集的歌曲越来越多,整理歌曲成了一件非常麻烦的事情,很多歌曲缺少歌词或者缺少封面等信息,于是想起来整理一下,以便以后的播放和保存。
1、最强音乐整理软件:MP3tag
Mp3tag 是一个功能强大且易于使用的工具,用于编辑音频文件的元数据。它支持批量标签编辑 ID3v1,ID3v2.3,ID3v2.4,iTunes MP4,WMA,Vorbis 评论和 APE 标签,可同时覆盖各种音频格式的多个文件。此外,它还支持来自 Discogs,MusicBrainz 或 freedb 的在线数据库查找,允许您自动收集适当的标签并下载音乐库的封面。您可以根据标记信息重命名文件,替换标记和文件名中的字符或单词,导入/导出标记信息,创建播放列表等。
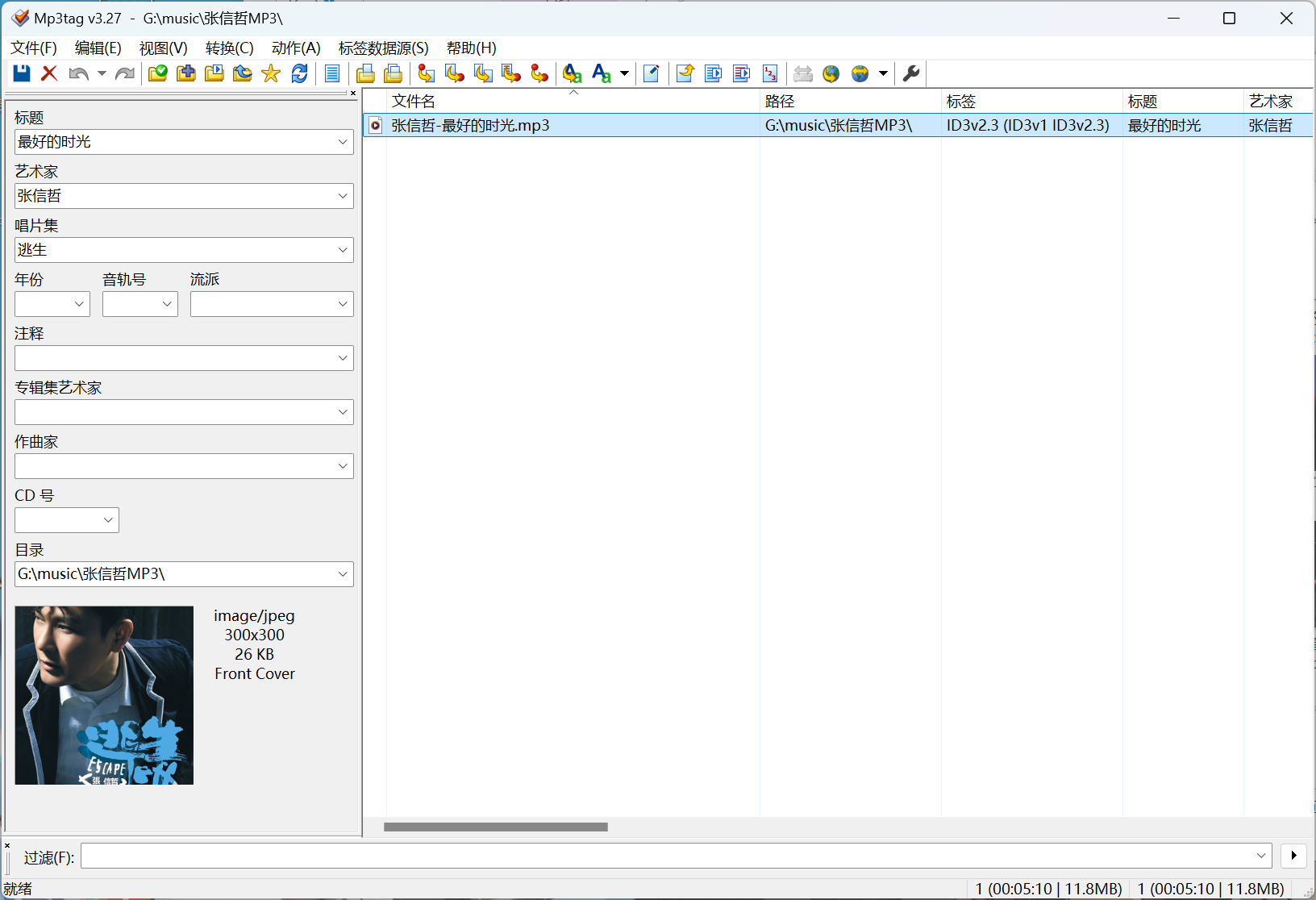
说这么多,也是免费,开心。我用到的主要有这几个功能
- 批量删除多余的广告等信息;
- 将歌词和封面批量添加到响应音乐种;
- 歌曲名字、专辑等名字乱码修复。
当然除了这些功能之外,这个软件其他的功能也是非常强大的,批量修改文件名字,修改标签等等都是非常的简单,本来软件也是可以使用标签数据源,像豆瓣、虾米等等之类的数据源自动的下载并添加封面专辑等信息的,但是由于这些数据源长时间没有人维护,现在网上能找到的基本就是好多年前的了,都不能使用了。
下面也会详细来说说我使用到的几个功能,更多详细的使用功能和步骤可以在Mp3Tag 教程这里面找到。
2、歌曲整理步骤
2.1 下载歌曲
现在能下载歌曲的网站还是挺多的,但是普遍存在歌曲的标签不完善或者标注错误的情况,所以下载网站的选择直接关系到后续整理歌曲的难易程序。这里我选择的主要下载网站主要是:
- 首选各种pt站点的资源,通常pt网站里面的歌曲整理算是最规范的了;
- 其次是一些运营比较好的网站,比如HiFiNi - 音乐磁场,但是这是一个收费的网站,一年10块钱就可以一直下载了,价格还算能接受的;
- 最后就是一些免费分享的网站了,比如熊猫无损音乐,是一个比较大的音乐网站并且还是免费的,但是缺点是音乐的标签非常的不完善而且里面还带有广告。还有这个网站是禁止外网访问的,记得关掉代理再尝试。
我这里主要下载无损音乐的地方是用的熊猫无损音乐,主要还是熊猫有提供很多的合集包可以直接下载不用再一首一首的找了,后面也会通过 MP3tag 软件对里面存在的一些问题进行修复。如果想在 pt 里面下载那就只能自己想办法了,可以去论坛或者贴吧求点邀请,对于想使用 HiFiNi 下载的可以看我之前的自制桌面小猫咪(坑还没填完...)的教程实现自动搜索下载。
2.2 下载歌词 封面
对于很多歌曲中是没有封装歌词和封面的,像之后用到的音流--播放软件就是不支持外挂歌词,只能使用内置的歌词,因此就需要下载歌曲的对应歌曲和歌词然后将其封装到歌曲里面。
首先要解决的就是去哪里下载的问题,目前说主流的音乐软件就是QQ音乐和网易云音乐,网易云是最容易获取的,但是很多的歌曲都是没有版权的,因此这里选择QQ音乐作为歌词和封面的下载源。
下载的源找到了,那么下一步就是准备进行批量下载了,这里需要完成两件事,一个是搜索,再一个就是下载。搜索可以直接使用爬虫调用QQ音乐的搜索接口就可以直接获取到搜索结果了,但是想要根据搜索结果获取歌词和封面是有问题的,QQ音乐会强制让你登录。
这里就要用到另一个神器了--[Meting-API](xizeyoupan/Meting-API: 🐳 Meting API 的容器化与部署),其能够支持多种常用的音乐平台,但是音乐源文件下载很多都是不能用了,只能下载个封面和歌词还是可以的,这就正好符合要求了。
| server参数名称 | 图片 | 歌词 | url | 单曲/song | 歌单/playlist | 歌手/artist | 搜索/search | |
| 网易云 | netease | √ | √ | √ | √ | √ | √ | √ |
| qq音乐 | tencent | √ | √ | √ | √ | √ | × | × |
| youtube music | ytmusic | √ | √⁰ | √ | √ | √ | × | × |
| spotify | spotify | √ | √⁰ | √⁰ | √⁰ | √⁰ | × | × |
下载歌词 封面的代码
import json
import re
import time
import requests
import os
def list_all_files(directory):
try:
# 获取指定目录下的所有文件和子目录
files = [f for f in os.listdir(directory) if os.path.isfile(os.path.join(directory, f))]
return files
except FileNotFoundError:
return f"目录 {directory} 不存在"
def search(name):
res = requests.get(f"https://c6.y.qq.com/splcloud/fcgi-bin/smartbox_new.fcg?_=1729862842408&cv=4747474&ct=24&format=json&inCharset=utf-8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=1&uin=0&g_tk_new_20200303=1650389286&g_tk=1650389286&hostUin=0&is_xml=0&key={name}")
if res.status_code != 200: # 如果使用 cookies 登录失败,重新登录
return False
json_list = json.loads(res.text)
return json_list["data"]["song"]["itemlist"]
def get_pic(ids, name, file1):
res = requests.get(f"https://meting.xinling.site/api?server=tencent&type=pic&id={ids}", verify=False)
if res.status_code == 200:
# 将下载的文件保存到本地
# with open(f"./uploads/{name}.jpg", 'wb') as file:
folder_path = file1 + "pic"
if not os.path.exists(folder_path):
# 如果不存在,则创建文件夹
os.makedirs(folder_path)
with open(f"{folder_path}/{name}.jpg", 'wb') as file:
file.write(res.content)
return True # 下载成功
else:
return False # 下载失败
def get_lrc(ids, name, file1):
res = requests.get(f"https://meting.xinling.site/api?server=tencent&type=lrc&id={ids}", verify=False)
if res.status_code == 200:
# 将下载的文件保存到本地
folder_path = file1 + "lrc"
if not os.path.exists(folder_path):
# 如果不存在,则创建文件夹
os.makedirs(folder_path)
# with open(f"./uploads/{name}.lrc", 'wb') as file:
with open(
f"{folder_path}/{name}.lrc",
'wb') as file:
file.write(res.content)
return True # 下载成功
else:
return False # 下载失败
def is_valid_format(input_string):
"""判断输入是否符合 '数字-数字' 的格式"""
pattern = r'^\d+.\d+$' # 正则表达式:以数字开头,后跟'-',再跟数字,且两者均为完整数字
return bool(re.match(pattern, input_string))
def get_qq_pci_lrc(file, num=0):
file_list = list_all_files(file)
for lis in range(num, len(file_list)):
li = file_list[lis]
aother = li.split("-")[0].replace('dj', '').strip()
total_song = li.split("-")[1]
search_song = re.sub(r'\(.*?\)', '', total_song)
search_song = search_song[:-4]
down_song = total_song[:-4]
total_name = f"{aother}-《{down_song}》"
while True:
try:
name_list = search(f"{aother.replace('&', '/')} {search_song}")
break
except:
print("搜索失败,正在重新搜索。。。")
time.sleep(5)
if name_list:
pic = get_pic(name_list[0]['mid'], li, file)
lrc = get_lrc(name_list[0]['mid'], li, file)
if pic and lrc:
print(f"{lis} {total_name} ➡ {name_list[0]['singer']} {name_list[0]['name']} pic lrc 下载成功")
continue
for index, li1 in enumerate(name_list):
print(f"{index}: {li1['singer']} {li1['name']}")
print("⬆")
while True:
try:
name_list1 = search(f"{search_song}")
break
except:
print("搜索失败,正在重新搜索。。。")
time.sleep(1)
if not name_list1:
print("未搜索到数据,跳过")
continue
for index, li1 in enumerate(name_list1):
print(f"{index}: {li1['singer']} {li1['name']}")
print("⬆")
print(f"{lis} {total_name} 请输入需要下载序号:")
num = input()
if is_valid_format(num):
fist = int(num.split(".")[0])
fist1 = int(num.split(".")[1])
if fist == 0:
pic = get_pic(name_list[fist1]['mid'], li, file)
lrc = get_lrc(name_list[fist1]['mid'], li, file)
if pic and lrc:
print(f"pic lrc 下载成功")
else:
print("下载失败")
elif fist == 1:
pic = get_pic(name_list1[fist1]['mid'], li, file)
lrc = get_lrc(name_list1[fist1]['mid'], li, file)
if pic and lrc:
print("pic lrc 下载成功")
else:
print("下载失败")
if __name__ == '__main__':
file = "赵雷"
file1 = f"G:/music/{file}MP3"
file2 = f"G:/music/{file}WAV"
get_qq_pci_lrc(file2, 0)
2.3 wav 转 flac
WAV格式:
- WAV通常不进行压缩,是一种无压缩的音频格式。它保留了音频数据的原始质量,因此文件体积较大。
- WAV 文件本身并不原生支持复杂的元数据标签。尽管可以使用 RIFF标准的 "INFO" 或 "LIST" 区块来存储简单的元数据(如标题、作者、专辑名等),但是这种支持非常有限,并且没有标准化的方式来处理诸如封面艺术、歌词、年份等信息。
- WAV标签因其容量有限通常无法在标签部分存储音乐的封面、歌词等
FLAC格式:
- FLAC是一种无损压缩音频格式,意味着音频质量不会丢失,但它会将音频数据压缩,从而减少文件的大小,通常压缩率在30%-60%之间。
- FLAC 格式则有更完善的标签支持,基于标准的 Vorbis comment 格式。
- FLAC 格式的标签更为标准化,支持完整的 ID3 标签风格,且这些标签可以在 FLAC 文件中嵌入并跨平台兼容。FLAC 文件的元数据可以轻松地在多种音频播放器中显示和编辑。
很多平台下载的歌曲的格式还是 WAV 格式的,因此需要将 WAV 格式的歌曲文件转成 FLAC 格式的文件,需要注意的是转成 FLAC 文件格式之后会将之前的封面和歌词之类的全部清除掉。直接使用python进行批量处理就可以了。
import os
import ffmpeg
def convert_wav_to_flac(input_file, output_file):
(
ffmpeg
.input(input_file)
.output(output_file, format='flac', acodec='flac', map='0:a', map_metadata='0') # 保留音频流和元数据
.run()
)
def batch_convert_wav_to_flac(folder_path):
index1 = 0
for filename in os.listdir(folder_path):
if filename.endswith('.wav'):
input_file = os.path.join(folder_path, filename)
output_file = os.path.join(folder_path, os.path.splitext(filename)[0] + '.flac')
print(f'正在转换: {index1}. {input_file} -> {output_file}')
convert_wav_to_flac(input_file, output_file)
print(f'转换完成: {index1}. {output_file}')
index1 = index1 + 1
if __name__ == '__main__':
dir2 = 'G:/music/赵雷WAV'
# 将wav文件转为flac文件
batch_convert_wav_to_flac(dir2)
2.4 删除广告
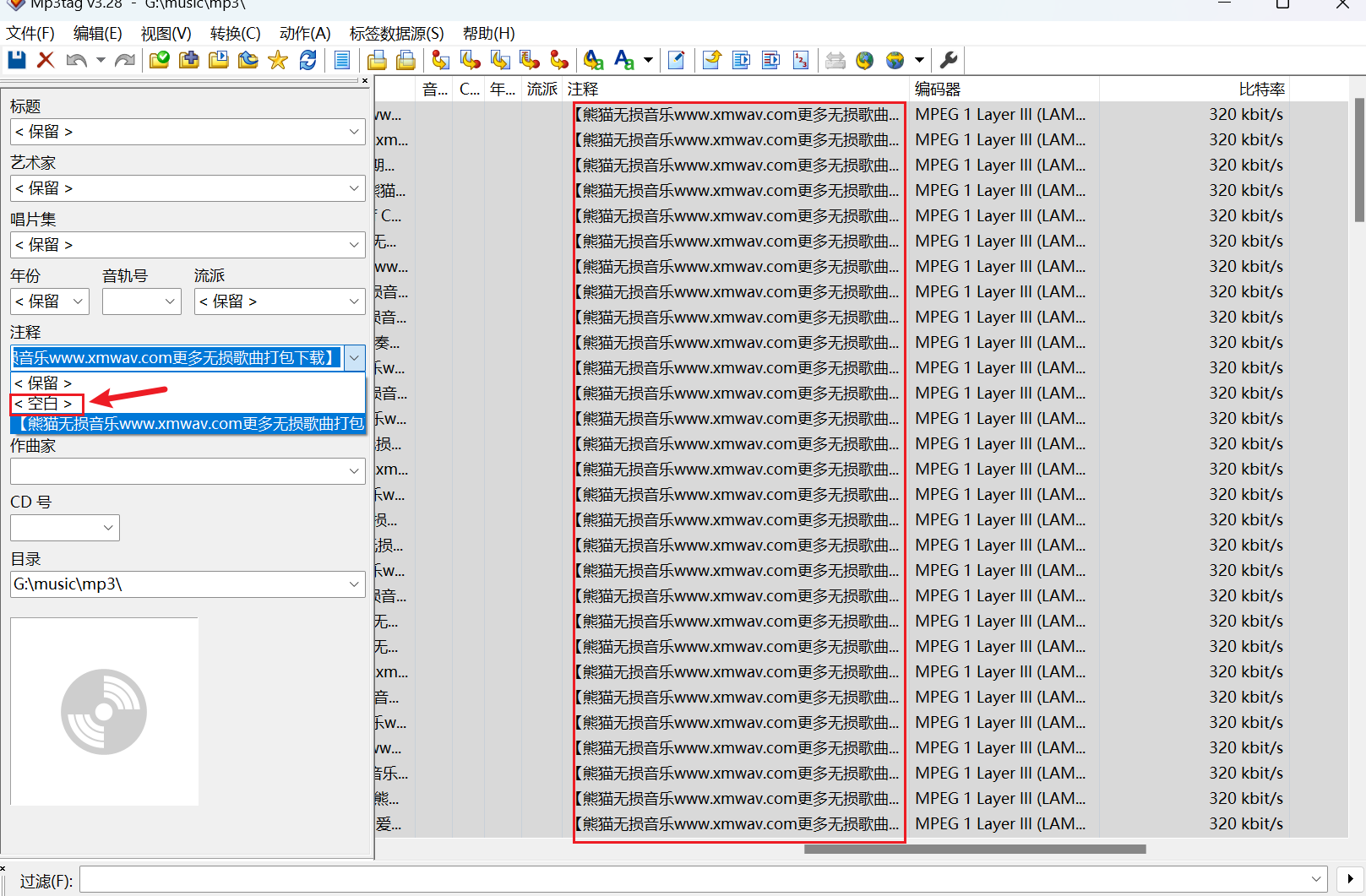
在网站上面下载下来的歌曲在里面有很多的广告,可以使用 MP3tap 批量删除掉,Ctrl + A 全选全部歌曲然后在左侧点击注释然后选择 空白 将这部分清除掉,清除完成之后一定要记得点保存或者 Ctrl + S 。
2.5 删除复合广告
对于上面那种全都是广告的情况可以用软件直接批量的清除,但是还有一种很恶心人的广告,就是和把广告和歌曲的一些信息填在一起的,就像下面这个样子
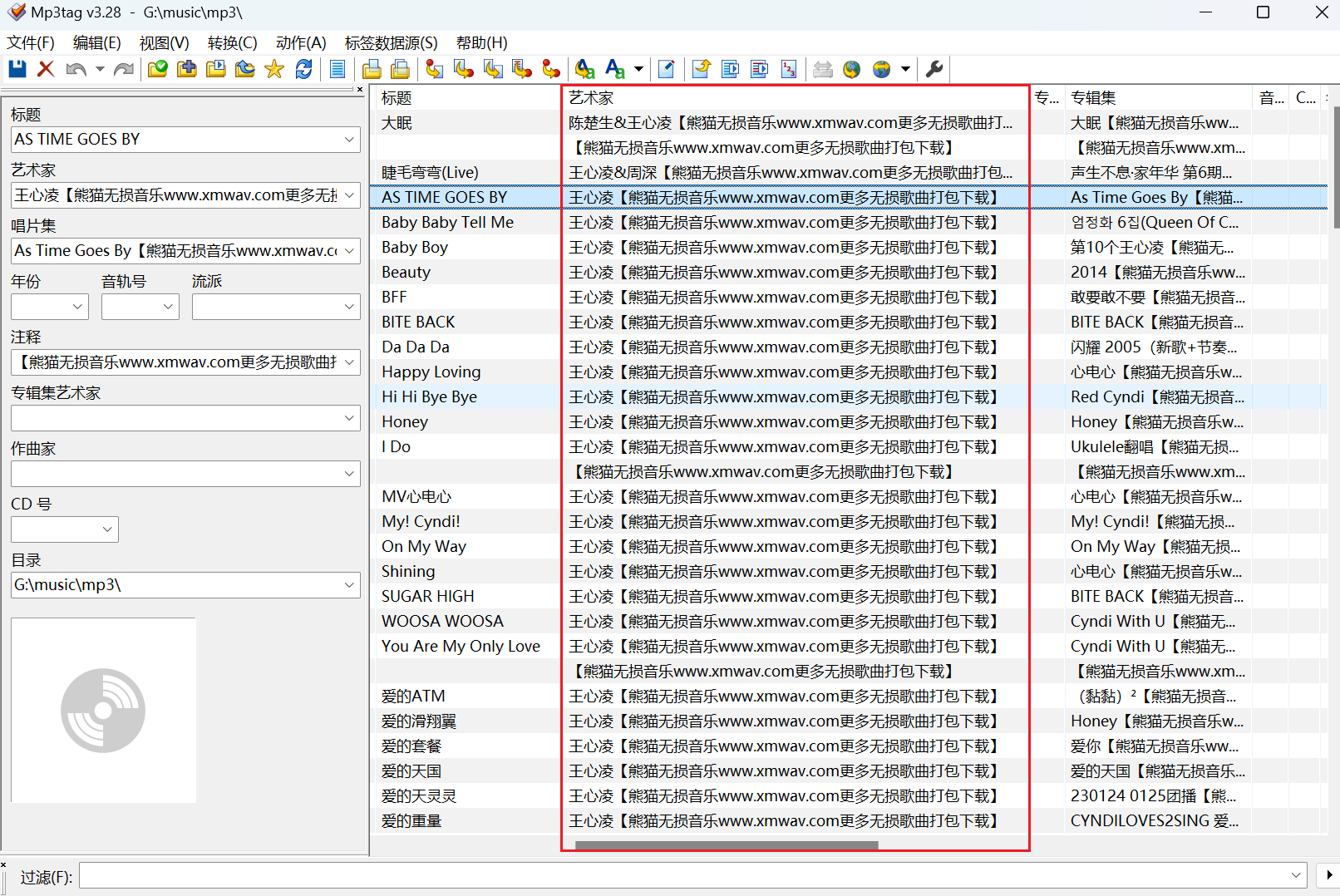
这种情况就不能直接全部清除了,不然艺术家这个重要信息也会被一起清除掉。这里就只能使用 python 读取音乐文件的标签信息然后删除对应的广告了。
import os
import ffmpeg
import re
import re
from mutagen.easyid3 import EasyID3
from mutagen.flac import FLAC
# 清理元数据中的指定字符串
# 【熊猫无损音乐www.xmwav.com】更多打包资源下载
def clean_metadata_text(text, pattern="【熊猫无损音乐www.xmwav.com】更多打包资源下载"):
return re.sub(pattern, "", text)
# 读取并清理 MP3 文件的元数据
def clean_mp3_metadata(file_path):
audio = EasyID3(file_path)
# 检查并清理歌手和专辑字段
if "artist" in audio:
audio["artist"] = [clean_metadata_text(audio["artist"][0])]
if "album" in audio:
audio["album"] = [clean_metadata_text(audio["album"][0])]
audio.save()
# 读取并清理 FLAC 文件的元数据
def clean_flac_metadata(file_path):
audio = FLAC(file_path)
# 检查并清理歌手和专辑字段
if "artist" in audio:
audio["artist"] = [clean_metadata_text(audio["artist"][0])]
if "album" in audio:
audio["album"] = [clean_metadata_text(audio["album"][0])]
audio.save()
# 清理音频文件的元数据(自动选择格式)
def clean_audio_metadata(file_path):
if file_path.lower().endswith(".mp3"):
clean_mp3_metadata(file_path)
elif file_path.lower().endswith(".flac"):
clean_flac_metadata(file_path)
else:
print(f"不支持的文件格式:{file_path}")
# 清理文件夹下所有 MP3 和 FLAC 文件的元数据
def clean_folder_metadata(folder_path):
for root, _, files in os.walk(folder_path):
for file_name in files:
file_path = os.path.join(root, file_name)
if file_name.lower().endswith((".mp3", ".flac")):
print(f"正在清理文件: {file_path}")
clean_audio_metadata(file_path)
def convert_wav_to_flac(input_file, output_file):
(
ffmpeg
.input(input_file)
.output(output_file, format='flac', acodec='flac', map='0:a', map_metadata='0') # 保留音频流和元数据
.run()
)
if __name__ == '__main__':
# 对比两个文件的内容
dir1 = 'G:/music/赵雷MP3'
dir2 = 'G:/music/赵雷WAV'
# 去掉文件中的【熊猫无损音乐www.xmwav.com】更多打包资源下载
clean_folder_metadata(dir1)
2.6 封装歌词 封面
终于来到了最后一步了,经过上面对音乐文件的处理之后就能正式将封面和歌词封装到音乐标签里面了,这里还是使用 MP3tag 这个软件
-
点击 动作
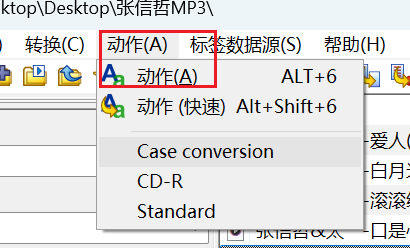
-
点击 新建 添加个 动作组的名字 点击 确定
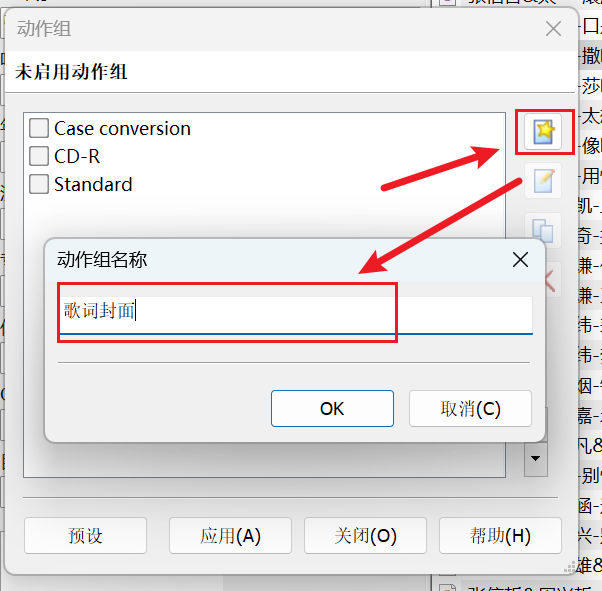
-
点击 新建 添加个 从文件导入专辑封面 点击 确定
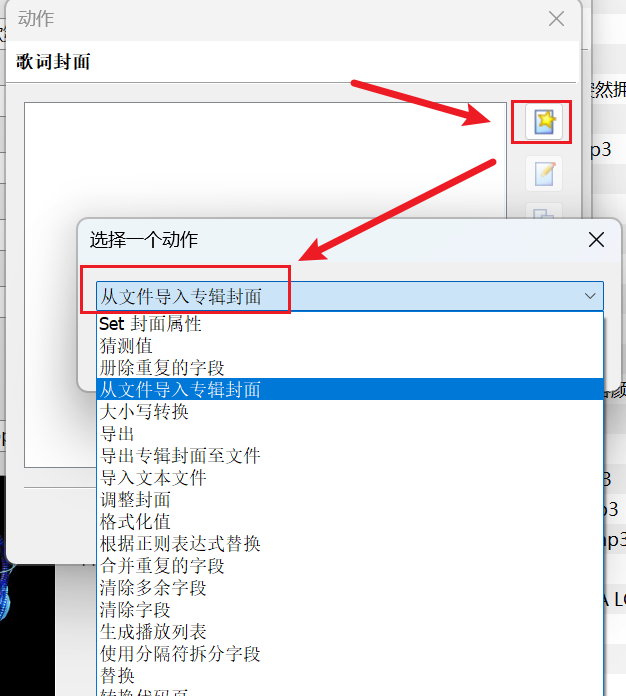
-
输入 %_path%%filetype%.jpg ,记得图片的命名格式需要是 音乐名字.mp3.jpg 的格式这样才能够被正确的识别
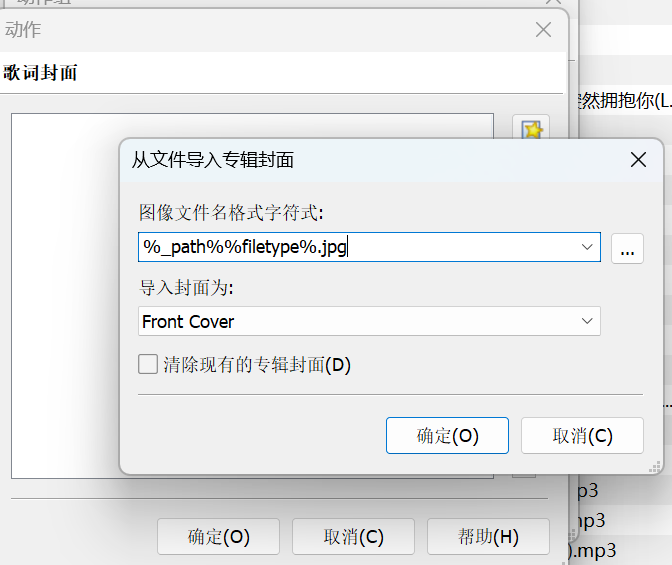
-
再添加一个歌词的动作, 选择 导入文本文件 点击 确定
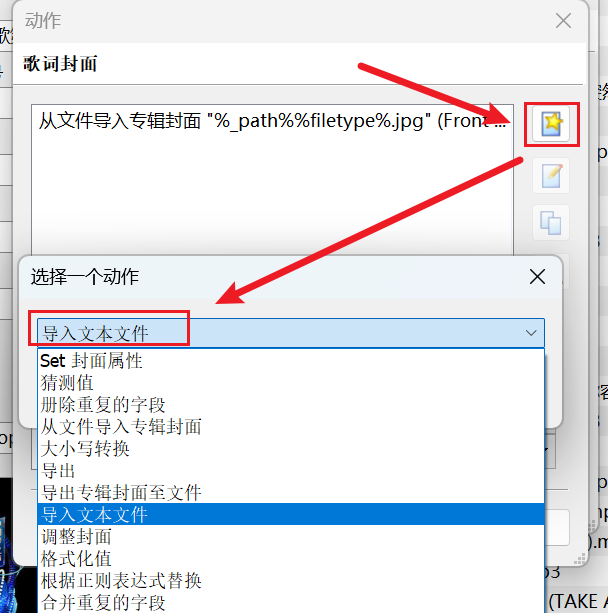
-
下拉选择 UNSYNCEDLYRICS 字段,文件名输入 %_path%%filetype%.lrc,同样歌词也需要是 音乐名字.mp3.lrc 的格式
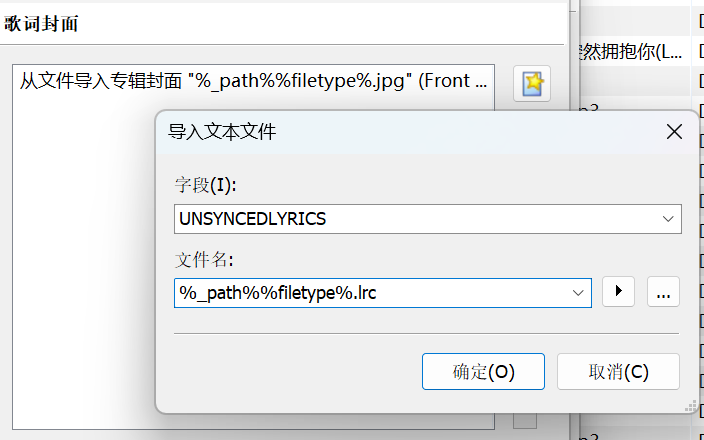
-
之后就可以直接使用了,Ctrl + A 全选全部歌曲然后选择动作,勾选刚刚添加的工作组,点击应用,之后程序会自动添加封面和歌词到每一首歌曲中。在运行完毕之后如果有没有识别到的会弹出来提示框,可以根据提示进行检查,运行完毕之后记得再点一次保存或者 Ctrl + S,防止有的歌曲没有保存上 。
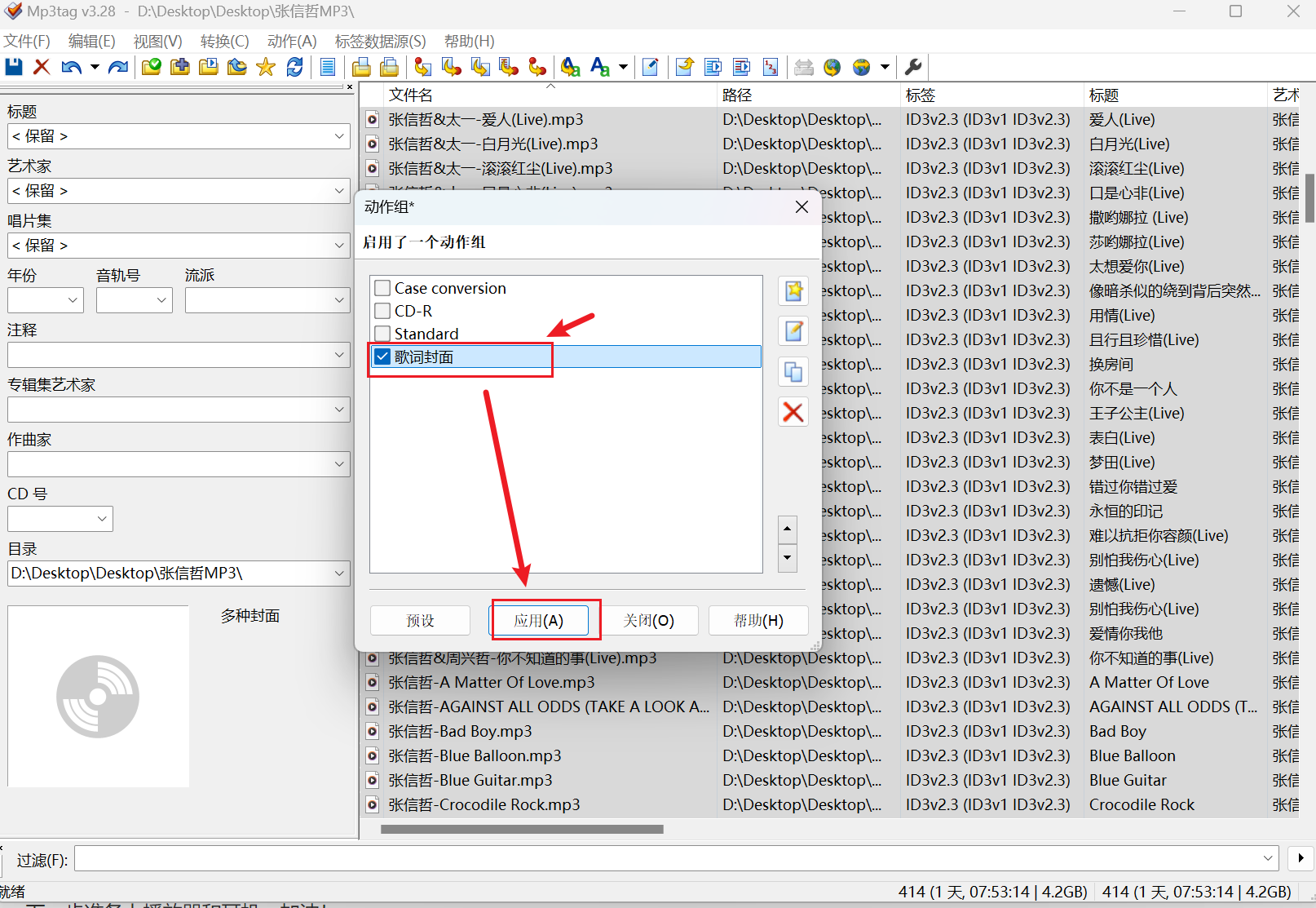
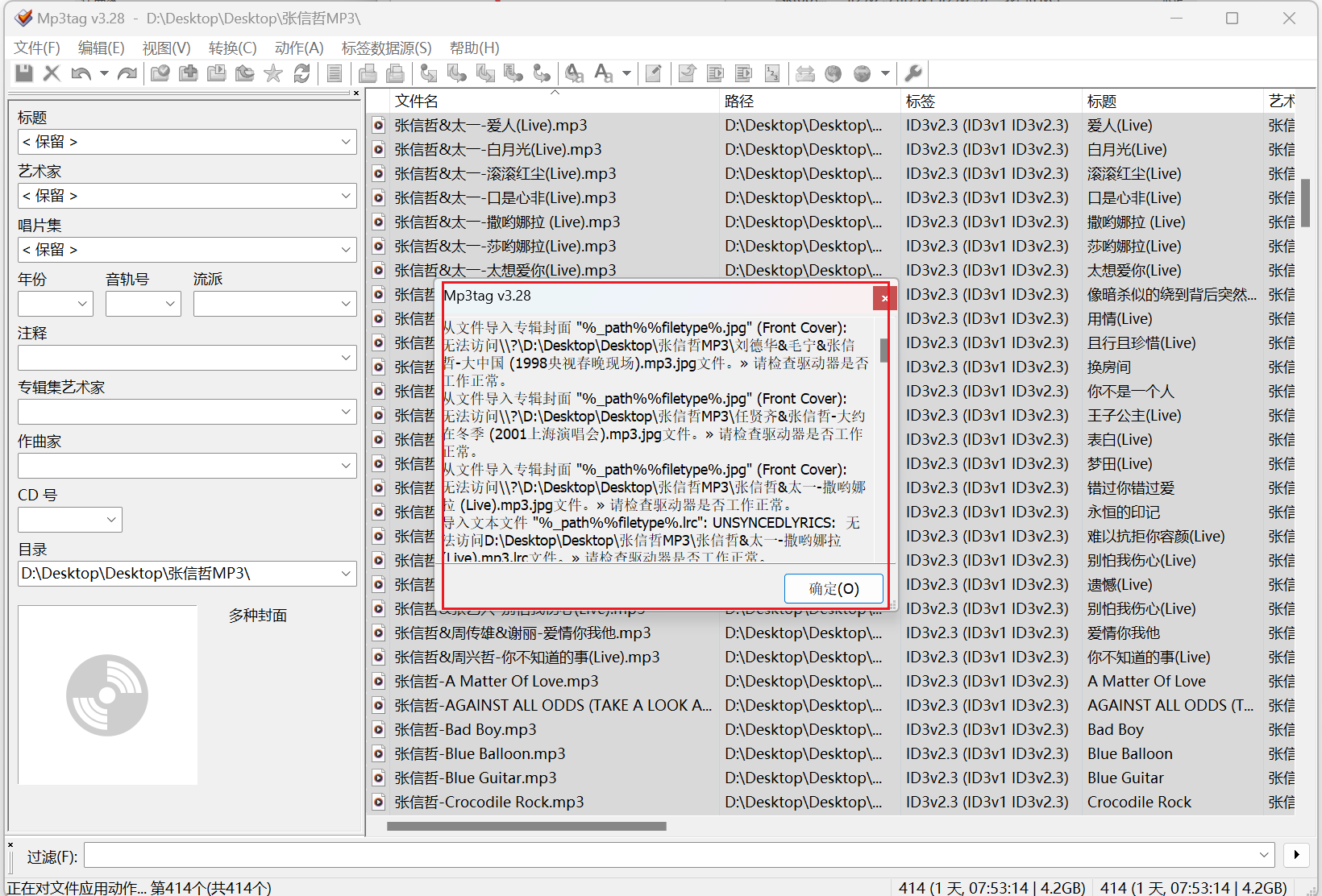
至此,终于完成了对音乐的整理步骤,步骤还是挺多的,现在音乐确实不如像电影的那样的命名和整理规范,而且由于QQ音乐版权问题,绝大部分的歌曲都只能在这里面听非常的的难受,只能我们自己动手整理了。
3、音乐播放软件的选择
就我个人使用体验来讲,目前并不存在完美的音乐服务,它们各有优缺点,需要根据自己的需求酌情选择。
支持版本
- Navidrome 0.49.3 及以上
- Plex 1.29.2 及以上,支持 OTP 验证码登录,暂不支持登陆到共享音乐库
- AudioStation DSM 6 及以上,支持 OTP 验证码登录
- Emby 4.7.14.0 及以上
- Jellyfin 10.8.10 及以上
- Subsonic 1.15.0 及以上
功能比较
| Subsonic | Navidrome | Audio Station | Emby | Jellyfin | Plex | |
|---|---|---|---|---|---|---|
| 内嵌歌词1 | - | ✅ | ✅ | ✅ | ||
| 外置歌词 | - | ✅ | ✅ | ✅ | ✅ | |
| 在线歌词 | - | ✅ | ✅ | ✅ | ✅ | |
| 歌手简介 | - | ✅ | ✅ | ✅ | ✅ | |
| 歌手头像 | - | *2 | *3 | ✅ | ✅ | ✅ |
| 多艺术家 | - | - | ✅ | ✅ | ||
| 回放增益 | - | ✅ | ✅ | ✅ | ||
| 评分功能4 | ✅ | ✅ | ✅ | ✅ | ||
| 收藏功能5 | ✅ | ✅ | ✅ | ✅ | ||
| 文件夹 | - | ✅ | ✅ | ✅ | ||
| 删除接口 | - | ✅ | ✅ | ✅ |
- 自 1.2.8 起,音流开启边听边存后可读取音乐文件内嵌歌词。
- Navidrome 若要显示歌手头像,需要配置 Spotify API(国内环境即使配置了也很难有作用),或在歌手文件夹下放一张名为 artist.* 的图片。Artwork location resolution
- Audio Station 的歌手头像用的是音乐库中的专辑图片。
- Audio Station 只能对歌曲评分。
- Audio Station 和 Plex 没有收藏功能,音流会将评级为 🌟🌟🌟🌟🌟 的歌曲视为收藏的歌曲。
现在能支持多端音乐播放的软件非常的少,目前用的比较好的就是--音流,其他的都或多或少的缺点有点多的。
4、结语
好了,到这里差不多了,将自己的一点心得体会记录下
下一步准备上播放器和耳机,加油!
最后再提供几个比较使用的代码
-
对比 MP3 和 WAV 两个文件夹里面的歌曲是否能够对应上,主要用来将歌曲分为低音质和无损音质
import os def compare_directories(dir1, dir2): # 获取两个目录中的文件列表并去掉后缀 files1 = {os.path.splitext(file)[0] for file in os.listdir(dir1)} files2 = {os.path.splitext(file)[0] for file in os.listdir(dir2)} # 找出不相同的文件 only_in_dir1 = files1 - files2 only_in_dir2 = files2 - files1 # 打印结果 if only_in_dir1: print(f"仅在 {dir1} 中的文件(去掉后缀):") for file in only_in_dir1: print(file) else: print(f"{dir1} 中没有独有的文件(去掉后缀)。") if only_in_dir2: print(f"仅在 {dir2} 中的文件(去掉后缀):") for file in only_in_dir2: print(file) else: print(f"{dir2} 中没有独有的文件(去掉后缀)。") if __name__ == '__main__': # 对比两个文件的内容 dir1 = 'G:/music/赵雷MP3' dir2 = 'G:/music/赵雷WAV' compare_directories(dir1, dir2) -
重命名文件,主要用来将封面和歌词的以 .mp3.lrc 和 .mp3.jpg 这样结尾的文件重命名为 .lrc 和 .jpg 这样的形式
import os def rename(folder_path, name, rename): # 遍历文件夹中的所有文件 for filename in os.listdir(folder_path): # 检查文件是否以 .lrc 结尾 if filename.endswith(name): # 构建旧文件路径和新文件名 old_path = os.path.join(folder_path, filename) new_filename = filename.replace(name, rename) new_path = os.path.join(folder_path, new_filename) # 重命名文件 os.rename(old_path, new_path) print(f"已重命名: {old_path} -> {new_path}") if __name__ == '__main__': # 对比两个文件的内容 dir1 = 'G:/music/赵雷MP3' dir2 = 'G:/music/赵雷WAV' # 重命名文件 rename(dir1, ".jpg", ".flac.jpg")
评论区